



Sleepy People Don’t Speak Clearly
There is a common belief that sleep deprivation causes “slurred” speech. At the same time, most people who have stayed up all night sound pretty normal; as the following excerpts from the same subject indicate, there may be something different about the speech of sleepy people, but they don’t necessarily sound drunk.
Do people who are sleep-deprived in fact speak less clearly than when they are rested? Since speech recordings are easy to acquire, it would be very useful if we could devise a method of assessing a person’s level of fatigue from a speech signal. The goal of this project was to figure out a way to do that.
When people are told to produce particularly understandable speech, they produce what is called “clear” speech. Some of the difference comes from a slower speech rate, and more pauses, but a lot of it comes from crisper articulation. Vowels tend to sound a bit more different from each other in “clear” speech, but a bit more like “uh” in conversational speech. A word like “police” might sound more like “poe-lees” in clear speech, more like “blees” in conversational speech. However, the amount of the difference might be very small. To pick up these very small changes in the speech signal, we need to have a measurement method that can pick up lots of small differences. We have developed such a method based on the detection of acoustic landmarks in the speech signal (Stevens, 1991; Liu, 1995; Fell & MacAuslan, 2003).
In this paper, we have two goals. First, we would like to find out if sleep-deprivation actually causes speakers to speak differently from when they are rested. Second, we would like to find out if these differences are similar to those found between intentionally clear and ordinary conversational speech. Third, we would like to find out if we can use an automatic computer-based method to compare two speech samples, and determine which sample is more clearly articulated. To do so, we first examine the results of our method on “clear” vs. “conversational” speech samples that are known to differ in articulatory clarity. We then apply our method to speech recorded from the same subjects when they are in a normal, rested condition, and when they have been deprived of sleep for 34-58 hours.
Method:
Simply put, landmarks are points in time where important articulatory events, such as the puff of air emitted by a “p” sound, occur during speech. Such events are marked by particular patterns of abrupt change in the different frequencies of speech sounds. Fig. 1 shows an example of landmark detection in our system.
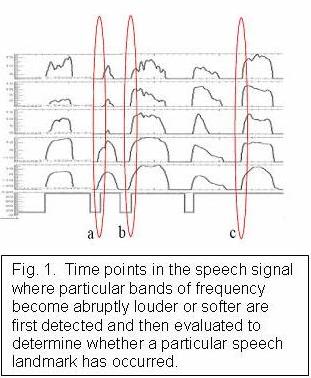
An important aspect of our system is that we use thresholding to determine whether or not a landmark actually occurred. In other words, a landmark is detected only if the speech patterns we are looking for are abrupt enough. If they are too soft or too gradual, a landmark is missed. Speech that is less crisply and clearly articulated will show fewer abrupt changes, and thus a different pattern of landmarks.
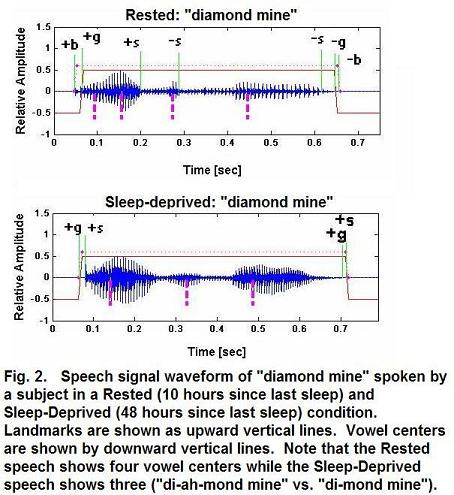
We can also use landmarks to look at changes in the syllable complexity of uttered speech. For example, the change from “poe-lees” to “blees” is a change from two simple syllables to a single complex syllable. (Notice that this change is just about how the word was said. The dictionary form of the word remains the same.) This change would be reflected in a change in the sequence of landmarks detected by the computer program. Fig. 2 shows a similar example for the phrase “diamond mine”. In the Rested condition, the word “diamond” is pronounced “di-ah-mond”, and it shows three vowel center landmarks. In the Sleep-Deprived condition, the word “diamond” is pronounced as “di-mond” and shows two vowel center landmarks.
In our studies so far, we have examined three datasets of sleep-deprived vs. normal speech, and three datasets of “clear” and “conversational” speech, for various landmark-based measures of differences, including voice onset time (VOT), number of landmarks, duration of strong and weak syllables, and syllable complexity. We have found statistically significant differences in a number of these measures for all datasets. An example of our results can be seen in Figures 3 and 4, which show the results of a comparison of syllable complexity between “clear” vs. “conversational” speech (Figure 3) and rested vs. sleep-deprived speech (Figure 4). In Figure 3, ten speakers, half male and half female, produced a large set of sentences in both speaking styles. Fig. 4 shows a similar analysis on a publicly available database of six people who produced speech at approximately 10 hours since last sleep, 34 hours, and 58 hours since last sleep. The statistical analysis used for both was a principal components analysis of the distribution of landmark clusters corresponding to syllable types in English. The axes of the graphs contrast the actual hours since sleep, or speaking style differences in intelligibility, against an estimated variable (SCORE) based on the differences in the distribution of landmark sequences corresponding to syllables. Both analyses were statistically significant at the p < .001 level.
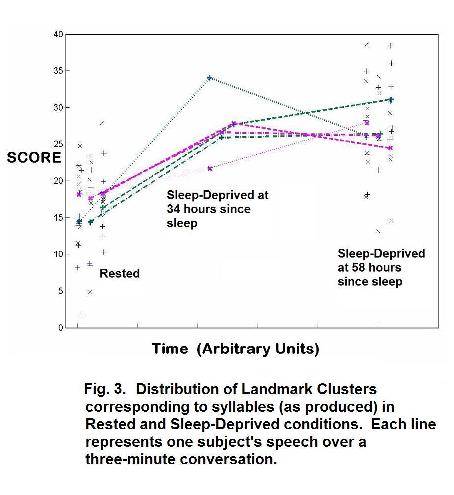
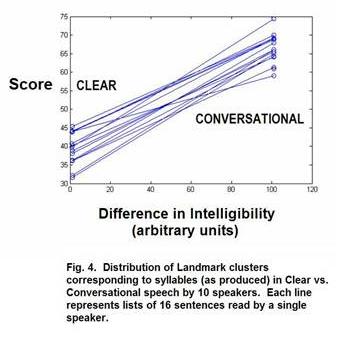
We conclude that people DO speak less clearly and crisply under sleep deprivation. These differences are too subtle to be called “slurring” but they can be detected by an automatic computer-based method based on landmarks. More research is needed to understand the physiological and cognitive reasons for these changes in speech, and to explore potential applications.
Main References:
Liu, S. (1995). Landmark detection in distinctive feature-based speech recognition. Unpublished Ph.D. dissertation. Cambridge, MA.
Stevens, K .N. (1991). Speech perception based on acoustic landmarks: Implications for speech production. Perilus XIV. Papers from the symposium, Current phonetic research paradigms: Implications for speech motor control.
Fell, H. J., MacAuslan, J., Cress, C. J.,& Ferrier, L. J. (2003). Using early vocalization analysis for visual feedback. Proceedings of the 3rdth International Workshop on Models and Analysis of Vocal Emissions for Biomedical Applications (MAVEBA, 2003), 39-42. .
The data for this work were originally collected under the aegis of the Defence and Civil Institute of Environmental Medicine North York, Ontario, Canada (DCIEM) and the Human Communication Research Centre University of Edinburgh & University of Glasgow, UK (HCRC), and were made available through the Linguistic Data Consortium at the University of Pennsylvania (www.ldc.upenn.edu). We also reference work done with colleagues Walter Carr, Thomas Balkin, Dante Picchioni, Tracy Rupp, and Allan Braun of Walter Reed Army Institute of Research (WRAIR), the United States Navy (U.S.N.) and the National Institute of Deafness and Other Communication Disorders of the United States (NIDCD). This work was funded in part by a research contract from the United States Air Force (U.S.A.F.) and by a grant from the National Heart, Lung and Blood Institute of the United States (NHLBI).