Acoustical Society of America
157th Meeting Lay Language Papers
Forensic Voice Comparison – Reality Not TV
Forensic Voice Comparison – Reality Not TV
Geoffrey Stewart Morrison - geoff.morrison@anu.edu.au
School of Language Studies, Australian National University
School of Electrical Engineering and Telecommunications, University of New South Wales
Popular version of paper 4aSCa6
Presented Thursday morning, May 21, 2009
157th ASA Meeting, Portland, OR
In February 2009 the National Research Council released its eagerly awaited report to Congress on "Strengthening Forensic Science in the United States." The report concluded that only nuclear DNA analysis had been demonstrated to reach the degree of reliability desirable for presentation of forensic evidence in court. Research and development of forensic DNA analysis has received substantial and consistent federal funding over many years, and the report strongly recommended similar investment in research and infrastructure development for other branches of forensic science, so that they can achieve similar high degrees of reliability. Internationally, a small number of researchers are already working on developing and implementing demonstrably reliable forensic-voice-comparison systems using the same framework as is used for the evaluation of DNA evidence.
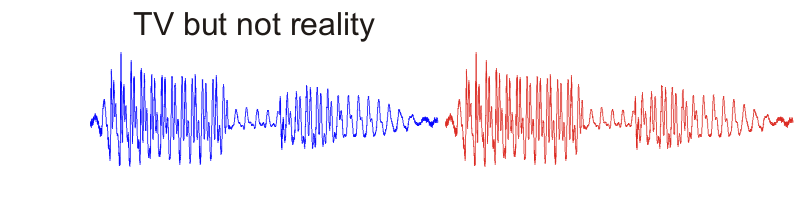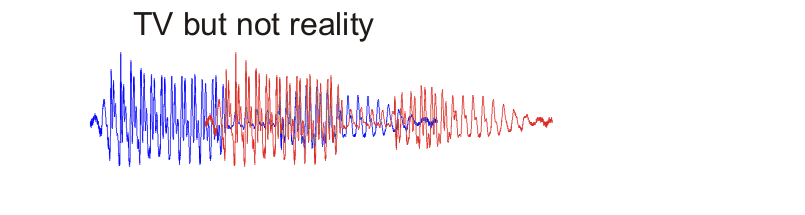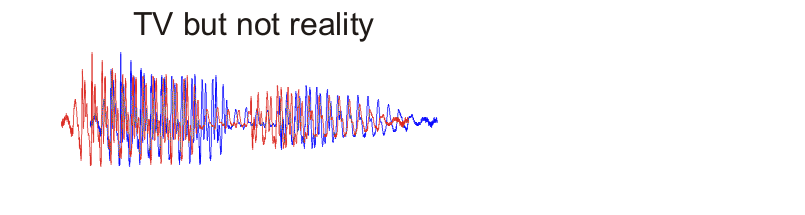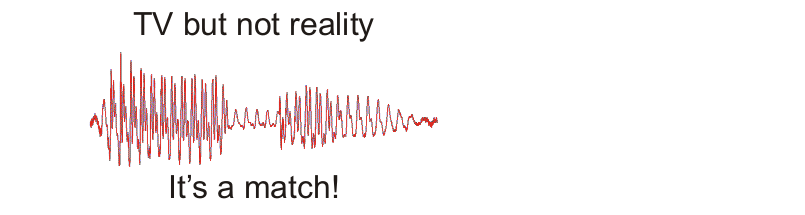
On TV a forensic scientist takes two speech recordings, displays them as waveforms on a computer screen, slides one waveform along until it lines up with the other, and shouts “It’s a match!” Reality is quite different, both in terms of acoustic analysis and in terms of the evaluation of forensic evidence.
First, a forensic scientist cannot say that two speech recordings are recordings of the same person (or that two DNA samples come from the same person). In order to do this they would need to have access to all sorts of information about the case which has nothing to do with a scientific analysis of the physical properties of the speech recordings, and even then not all relevant information would be available, and they would have to make some assumptions. It is the task of the jury, not the forensic scientist, to weigh all of the evidence presented to them and where necessary make assumptions. It is the jury, not the forensic scientist, who will decide whether the two voice samples came from the same speaker. The task of the forensic scientist is to help the jury by scientifically evaluating the samples provided to them and provide the jury with a statement as to the weight of that evidence, and that evidence alone.
Second, the weight-of-evidence statement that the forensic scientist presents depends not only on the similarity of the voice samples (or DNA samples), but also on the typicality of those samples. If two voice samples have very similar values on some acoustic measure, this does not mean that they were produced by the same speaker. If these acoustic values were very typical in the voices of the population at large, then pulling two samples from any two people in the population would be likely to result in equal or greater similarity. Mere similarity does not therefore lead to strong support for the hypothesis that the voice samples were produced by the same speaker. If, on the other hand, the acoustic values are similar and atypical in the population at large, then one would be unlikely to obtain these two values by picking samples at random from the population, and this would lend much stronger support to the same-speaker hypothesis. In general, more similarity and less typicality leads to greater support for the same-speaker hypothesis, and less similarity and more typicality leads to greater support for the different-speaker hypothesis.
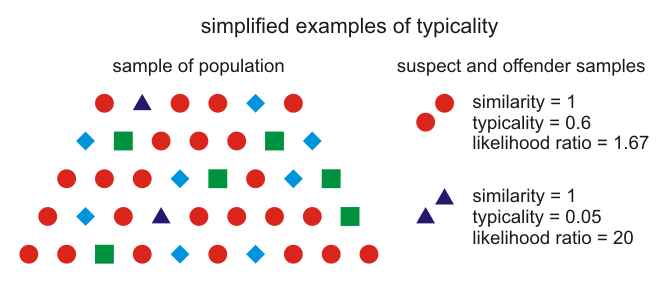
In forensic voice comparison, multiple acoustic properties of the known (suspect) and questioned (offender) voice samples are measured and assessed for similarity with each other and for typicality in relation to a database of voice samples which are representative of the population. This is done using statistical procedures to calculate a likelihood ratio, which is a numeric expression of the strength of evidence in answer to the question: How likely would one be to obtain the acoustic differences between these two voice samples under the (prosecution) hypothesis that they were produced by the same speaker, versus under the (defense) hypothesis that they were produced by different speakers.
Forensic scientists can measure the reliability of a forensic-voice-comparison system by testing it on a large number of pairs of voice samples which are known to be same-speaker or different-speaker pairs. Likelihood ratios of greater than one favor the same-speaker hypothesis and likelihood ratios of less than one favor the different-speaker hypothesis. The larger the likelihood ratios obtained from same-speaker comparisons and the fewer which are less than one, and the smaller the likelihood ratios obtained from different-speaker comparisons and the fewer which are more than one, the more reliable the system.
In some ways forensic voice comparison is actually more complicated than forensic DNA comparison. Unlike DNA profiles, voice samples will never “match”. Whereas (if we exclude a few possibilities such as transplants) DNA samples taken from the same person at different points in time will result in identical profiles, the acoustic properties of a speaker’s voice vary from occasion to occasion – the same speaker never says the same thing exactly the same way twice. In addition there will be contextual variation, the exact words and phrases used in each voice sample will almost certainly be different. The acoustic properties of voices are therefore subject to within-speaker variability. What makes a good feature for analysis in forensic voice comparison is a feature which has low within-speaker variability, does not change much from occasion to occasion, but which has high between-speaker variability, changes a lot from speaker to speaker.

Some good acoustic features for forensic voice comparison are the trajectories of formants in diphthongs. Formants are the resonant frequencies of the vocal tract, the properties which allow one to hear the difference between different vowels, for example the differences between the vowel in “hat” and the vowel in “heat”. Different mouth shapes result in different formant values – feel the difference in the shape of your mouth when you say the vowels in “hat” and “heat”. Diphthongs are vowels in which the shape of the mouth and therefore the frequencies of the formants change over time, for example the vowel in “height” begins like “hat” and ends like “heat”. The formant trajectories are the exact paths of the changes in formant values over time. Research has shown that only the initial and final formant values are needed for accurate vowel perception, and the exact path taken between these two points is not particularly important. Different speakers are therefore free to produce the formant trajectories which suit them best because of the peculiarities of the musculature of their tongue and the shape of the roof of their mouth etc.. Theoretically formant trajectories will therefore have low within-speaker variation and high between-speaker variation, and small-scale experiments based on measurements of format trajectories have found that these do indeed lead to extremely reliable forensic-voice-comparison results (details are given in Morrison’s research paper in the April 2009 issue of the Journal of the Acoustical Society of America).
Work is now underway on demonstrating reliability in larger-scale experiments, and funding is being sought to build the infrastructure needed to implement practical forensic voice comparison using these and other features.
Acknowledgments
This work was supported financially by Australian Research Council Discovery Grant No. DP0774115. Thanks to Dr. Philip Rose for comments on an earlier draft.
References
Morrison, G. S. (2009). Likelihood-ratio forensic voice comparison using parametric representations of the formant trajectories of diphthongs. Journal of the Acoustical Society of America, 125, 2387– 2397.
National Research Council (2009). Strengthening forensic science in the United States: A path forward. Washington, DC: National Academies Press.
About the presenter
Dr. Geoffrey Stewart Morrison is a forensic scientist specializing in forensic voice comparison. He received his PhD from the University of Alberta Department of Linguistics in 2006. He was the recipient of Doctoral and Postdoctoral Fellowships from the Social Sciences and Humanities Research Council of Canada. He is currently a Research Associate at the Australian National University School of Language Studies and a Visiting Fellow at the University of New South Wales School of Electrical Engineering and Telecommunications. He conducts research on improving the reliability of forensic-voice-comparison systems, particularly via the combination of acoustic-phonetic and automatic approaches. He is an active promoter of the adoption of the likelihood-ratio framework for the evaluation of forensic evidence. He presented a tutorial and organized a special session on forensic voice comparison at the International Speech Communication Association’s Interspeech conference, Brisbane, September 2008, and is an invited speaker at the 2nd International Conference on Evidence Law and Forensic Science, Beijing, July 2009.
http://geoff-morrison.net
http://forensic-voice-comparison.net