Francesco Tordini – tord@cim.mcgill.ca (corresponding author)
Albert S. Bregman
Jeremy R. Cooperstock
McGill University
Montreal, QC
Canada
Anupriya Ankolekar
Thomas Sandholm
Hewlett-Packard Laboratories
Palo Alto, CA
United States
Popular version of paper 2pAB11
Presented Tuesday afternoon, June 4, 2013
ICA 2013 Montreal
Imagine yourself walking downtown on a busy street. You are surrounded by a great number of sounds, but usually, attend only to a few. This pre-selection is effortless, somehow primitive and generally automatic. Moreover, it is vital to reducing the scene analysis to a simpler problem, thereby making it easier to focus our attention on one, or two, of the available sounds.
The saliency of a sound is what drives the pre-selection process above. A sound is considered to be salient when it is prominent with respect to other sounds, or more generally, with respect to a background. It can be seen as the probability that a sound event will emerge in a crowded auditory scene. Since it drives an effortless process, it should be possible to describe saliency in terms of elementary properties of the sounds populating the scene.
The first step towards a saliency model is, usually, the definition of a collection of features such as loudness, pitch, and energy that evolve over time together with a set of relationships and preliminary processing techniques to be used. Instead, our approach begins with an effort to gather the ground truth of how people rate sounds in terms of their saliency. This information is used to design and test the saliency model, and informs our choice of a limited set of features, or descriptors, of the saliency of a given sound with respect to a background.
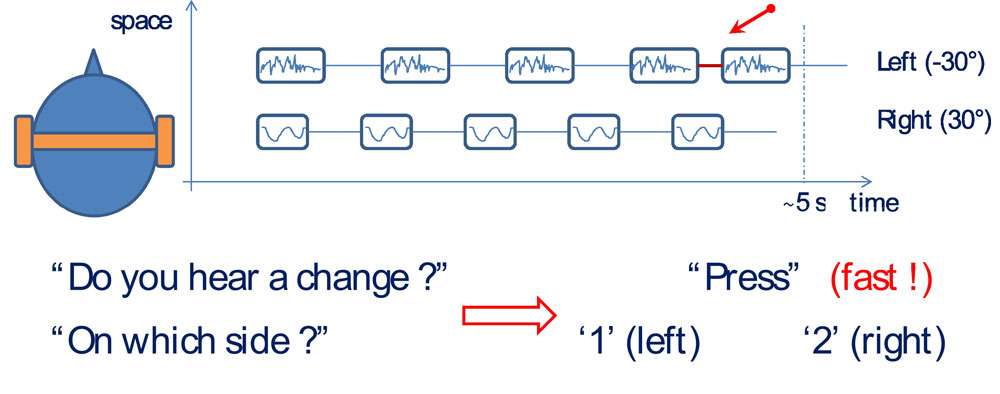
To gather the ground truth, we designed a listening task that is described in Figure 1. This aims to present a “closer to reality” listening scenario using repetitive, asynchronous and spatialized patterns of natural sounds having equal loudness. Our listening task represents an ecologically valid testing schema, using a binaural setup with real field recordings, thus addressing a shortcoming of previous approaches.
Figure 1: One trial of the SOAP Task (Segregation Of Asynchronous spatialized Patterns). Here Δt = 250 ms, Δt’ = 80 ms. Consecutive trials (groups of K chirps, with K = 5 in this example) are separated by 2.5 s
The SOAP task (Segregation Of Asynchronous spatialized Patterns) using bird chirps, presents two different sounds, one on each side of the head, each repeating with a constant tempo. When listeners detect a change in tempo (shortened time gap) on either side of their heads, they press one of two buttons to register their detections. We present here some preliminary results of our listening tests using bird chirp sounds, for which the spectrograms are shown in Figure 2.
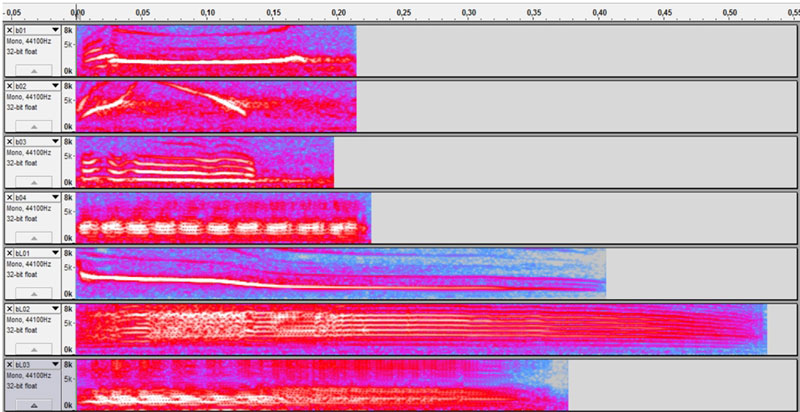
Figure 2: Spectrograms of the bird chirps used in our experiment. All sounds were monophonic, 16 bit, with Fs=44.1 kHz, peak- and loudness-normalized.
We find that detection accuracy and response time (RT) offer similar indications of sound saliency but the former is preferable, as being less sensitive to variables such as task design or sound complexity. We also find that using different backgrounds (silence, random noise, or speech babble) does not affect the saliency rating unless the background is loud enough to mask the bird sounds.
Most notably, our preliminary feature search showed that beyond loudness, which was equalized for our experiment, the effective duration (te) outperforms other “classical” pitch or energy-related descriptors in terms of saliency ranking prediction (see Table A). This measure can be extracted from the running autocorrelation function (ACF) of each sound.
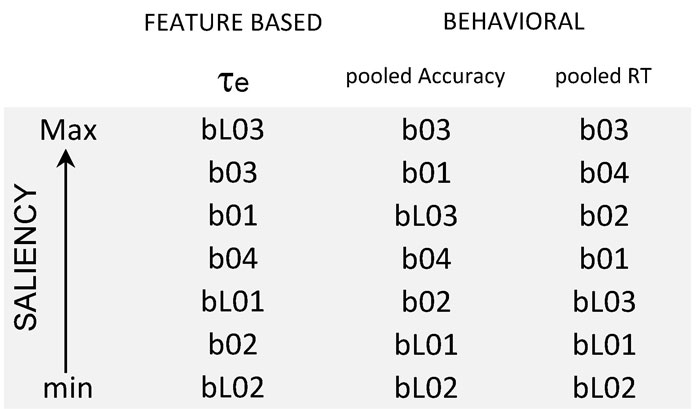
Table A: Saliency rankings from behavioural data (pooled accuracy and RT values) and from the effective duration (te) obtained from the autocorrelation function of each bird chirp.