
Talal Bin Amin – talal1@e.ntu.edu.sg
School of Electrical and Electronic Engineering
Nanyang Technological University, Singapore
James Sneed German – jsgerman@ntu.edu.sg
School of Humanities and Social Sciences
Nanyang Technological University, Singapore
Pina Marziliano – epina@ntu.edu.sg
School of Electrical and Electronic Engineering
Nanyang Technological University, Singapore
Popular version of paper 2pSCa4
Presented Tuesday afternoon, December 3, 2013
166th ASA Meeting, San Francisco
Have you ever tried to disguise your own voice? There are many ways to do this, such as by using a higher or lower pitch or by positioning the lips, tongue or throat in special ways. Now imagine trying to decide whether a voice you hear is a disguised voice or the speaker's natural voice. For human listeners in our study, this task proved challenging, with success rates at only 56% (virtually the same as guessing). By comparison, a computational measure we developed, which looks at fine-grained differences in how vowel sounds are phonetically "scattered," was able to distinguish disguised voices from natural ones with 92% accuracy.
The automatic detection of voice disguise is important for biometric systems where the speaker's voice is used as a means for authentication. In forensic scenarios, it is useful to know whether a kidnapper is using a disguised voice before attempting to uncover his true identity [1]. Currently, however, there are no automated methods which can reliably detect voice disguise. The goal of our study was to first explore the acoustic and linguistic characteristics of disguised voices, and then use the results to develop new methods for automatic detection of voice disguise.
Our study was based on a set of natural and disguised voices produced by three voiceover artists (i.e., professionals who are paid to record for commercials, cartoons, translated interviews, etc.). These artists (2 male, 1 female) were asked to provide fictitious character voices (or disguised voices) that varied in terms of social characteristics such as gender, age and personality. Each artist produced a total of nine different voices, including their natural one, while producing the same set of sentences. The artists chose the disguised voices freely, and our goal was to elicit as much variability as possible in terms of the strategies used by the artists to achieve their various voice identities.
During most types of speech the vocal cords are made to vibrate, much like the strings of a guitar, as air from the lungs passes between them. The frequency of these vibrations corresponds to the pitch of the voice, though the vibrations can vary in other ways as well. The amount of time that the vocal cords are either in contact or out of contact during a single cycle of vibration, for example, can lead to perceptible differences in how scratchy, breathy, or resonant a person's voice sounds. We used a device called an ElectroGlottoGraph (EGG) to observe such patterns in the different voices produced by our artists. This device is placed over the larynx on the outside of the neck (see Fig. 1), and uses electrical impedance to measure changes in the amount and strength of contact between the vocal cords over time.
Fig. #1: A voice artist recording with the EGG
The first part of our study compared the EGG signals across the different voice identities, and revealed that the artists are able to readily vary their vocal cord vibration patterns in order to achieve these different voice identities. The differences among patterns corresponded closely to differences that are known to exist across gender and age groups. Fig. 2 shows EGG waveform plots of the "natural" and "young" voices from the same speaker. The two voices differ in the amount of time that the vocal cords spend in contact as indicated by the ratio of the close phase over the time period.
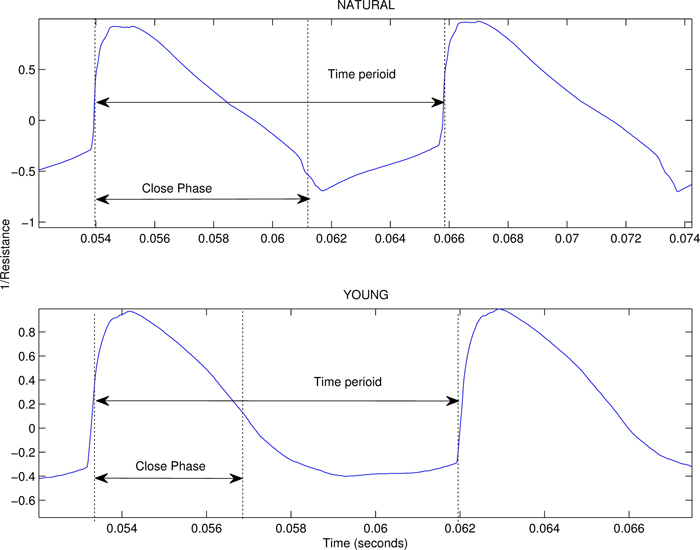
Fig. #2: The EGG signal for two voices by the same artist. The vocal cords remain in contact longer for the natural voice compared to the "young" voice.
The vibrational sound generated at the vocal cords eventually passes through the throat and mouth before being emitted into the surrounding air. The throat and mouth together form a kind of chamber called the vocal tract, the shape of which determines the timbre of the sound that gets emitted. Timbre is not only what makes a violin sound different from a clarinet, but it is also what makes one vowel sound different from another. (Think of singing "ee", "ah" and "oo" on the same note.) By changing the shape of the vocal tract using the tongue, lips, and jaw, a speaker can produce different timbres and, hence, different vowel sounds.
These differences are usually represented in a two-dimensional space, where the x- and y-axes correspond to the first two major energy peaks in the frequency spectrum. Fig. 3 shows how individual instances of vowel sounds are distributed in this space for one speaker in our study. In the figure, different vowel categories are represented by colors and different voices by shapes. Note that different regions in the formant space correspond to different timbres and are therefore either heard as different vowels or as slight variations of the same vowel. The clustering of individual voices within each vowel category suggests that the speakers in our study achieved different voice identities by making subtle changes to the timbre of individual vowels [2, 3].
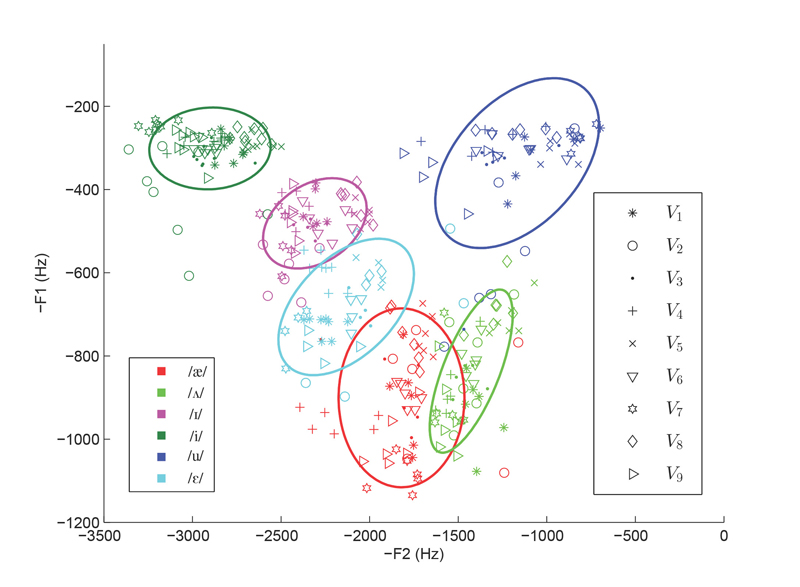
Fig. #3: Vowel distribution of a female producing nine different voice identities
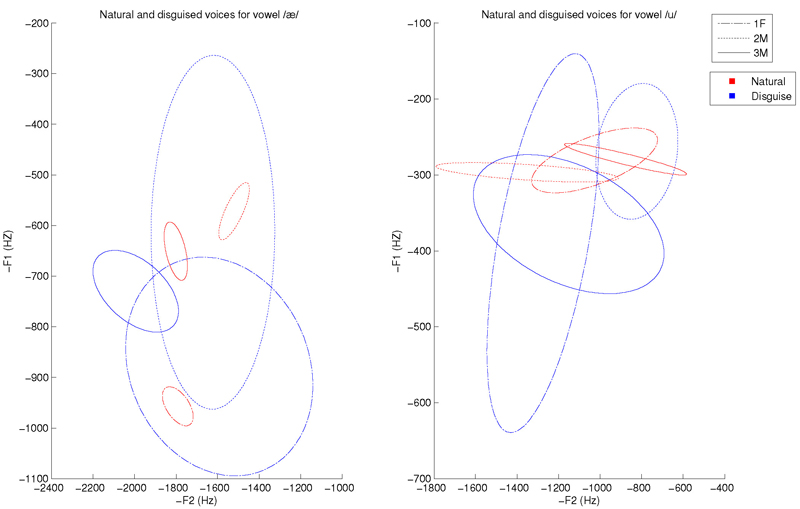
Fig. #4: The distribution of the natural and disguised voices of three artists for two vowels. There is significant overlap between the disguised and natural voices, though the natural voices occupy less area than the disguised voices.
The key finding in our study is that although the voice artists were very successful in deceiving humans, they nevertheless left small "traces" in their speech that we were able to use to detect voice disguise. Specifically, we discovered that disguised voices differ from natural voices in the way that the different instances of vowels are spread out in the two-dimensional space. In simple terms, the artists were more consistent with their timbre for the natural voices than for their disguised voices. This can be seen in Fig. 4 where the distribution of natural voice tokens (represented by red ellipses) occupies a much smaller region in the space compared to the distribution of disguised voice tokens (in blue). We used Principal Component Analysis (PCA) to model the scatter of different vowels for each voice. Fig. 5 shows the disguised and natural voices after performing the PCA transformation. The disguised voices (in blue) and natural voices (in red) are readily separated by a line drawn between them. This approach allowed us to automatically distinguish disguised and natural voices with 92% accuracy, which is much higher than human rate of 56%. Thus, these key differences between disguised and natural voices, which seem to be ignored by humans, can be used to automatically detect voice disguise.
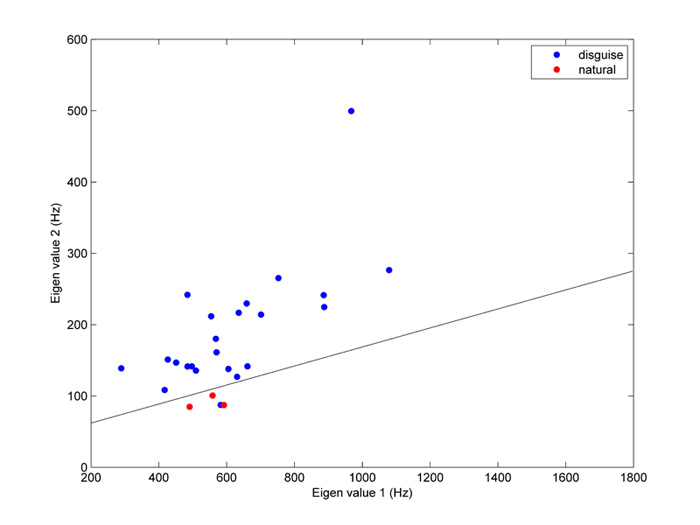
Fig. #5: The distribution of the voices in the PCA feature space. A line readily separates the disguised voices from the natural voices.
Audio samples
For audio samples of the voice identities, contact Talal Bin Amin.
References
P. Perrot, G. Aversano, and G. Chollet, "Voice disguise and automatic detection: review and perspectives," in Progress in nonlinear speech processing. Springer, 2007, pp. 101-117.
T. B. Amin, P. Marziliano, and J. S. German, (forthcoming) "Glottal and vocal tract characteristics of voice impersonators," Submitted to IEEE Transactions on Multimedia.
T. B. Amin, P. Marziliano, and J. S. German, "Nine Voices, One Artist: Linguistic and Acoustic Analysis," in IEEE International Conference on Multimedia and Expo (ICME), 2012, pp. 450-454.