Caroline Niziolek – cniziolek@ohns.ucsf.edu
Srikantan Nagarajan – sri@ucsf.edu
John Houde – houde@phy.ucsf.edu
University of California, San Francisco
513 Parnassus Avenue, Box 0628
San Francisco, CA 94118
Popular version of paper 4aSC4
Presented Thursday morning, December 5, 2013
166th ASA Meeting, San Francisco
Human speakers rely on auditory feedback, the sound of their own voices, to guide their speech. There is strong evidence that this feedback is used online by speakers to rapidly correct errors, but much of this evidence comes from experiments that impose artificial feedback distortions, making the vowel "a" come out sounding like "e," for example. This kind of experiment mimics a speech error, but the speaker did not actually make an error - not something that ever happens in the real world. To determine whether these error-correction processes are at work in natural speech, we used natural variability across many word productions to look for signs of error-related processing. We examined both speech acoustics and brain activity, measured using MEG (magnetoencephalography).
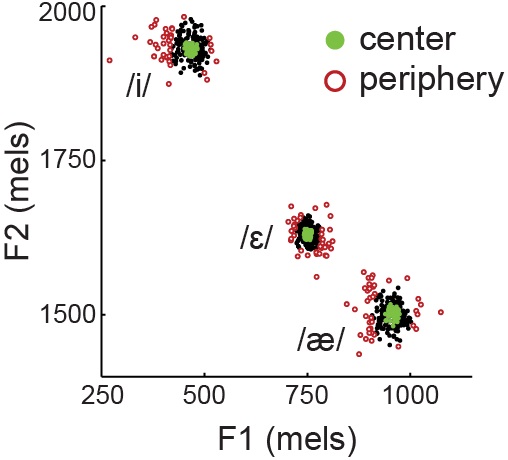
While in the MEG brain scanner, our experimental participants produced spoken words and also listened to passive playback of these same words. To elicit variability, we asked participants to produce the same three words ("eat", "Ed", and "add") two hundred times each, interleaved in a random order. Repeating the words this many times caused a distribution to emerge, with most of the sounds clustering near the center (Fig. 1, green dots) but some sounds lying at the edges, or periphery (Fig. 1, red dots). These outlying productions were least like the average or "typical" pronunciation of each of the words. Crucially, though, they did not sound like errors; they were merely the most error-like productions for each word.
Fig. #1: Distribution of the natural variability across vowel space for different vowels. /i/ = "eat"; / ɛ/ = "Ed"; / æ /= "add".
We looked at these error-like words at the periphery and analyzed how their sound changed over the course of each single word production (taking place within approximately 350 ms). We found that, overall, the sounds of these words changed to be more like the more typical word productions, moving towards the center of the distribution over a very short time (Fig. 2A). This is evidence that our word productions are driven to their intended target sounds.
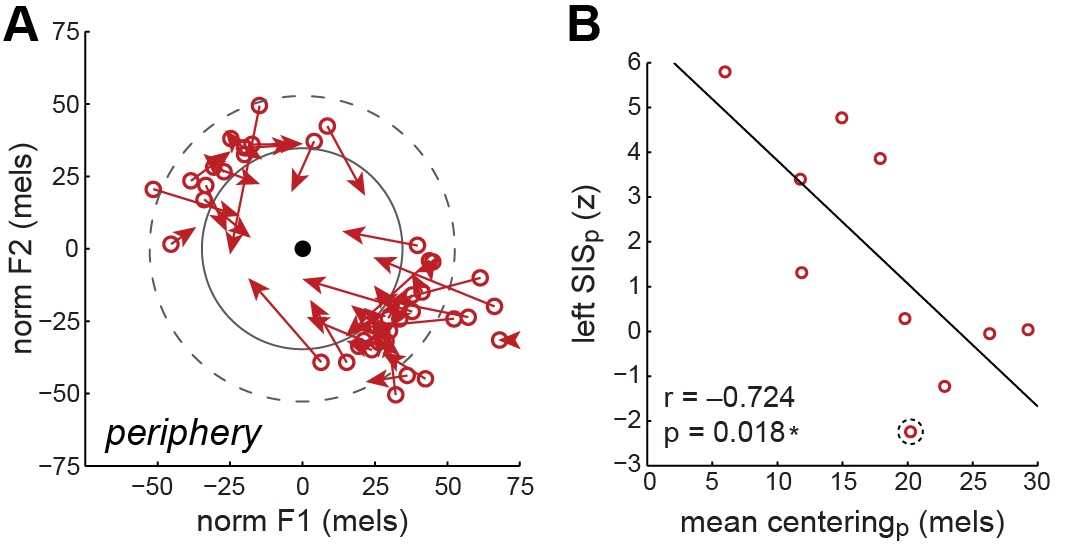
Fig. #2: Word productions at the periphery move inward towards the center, becoming less error-like. Each dot-arrow pair is a single word production. The dots show the starting point for each word at the periphery, and the tip of the arrow shows the midpoint of the word, approximately 150 ms later in time.
Does auditory feedback play a role in driving these corrections? To test this, we examined the MEG signal from auditory cortex, the part of the brain that processes sound, including speech. First, we found that auditory responses to the peripheral words were much greater than responses to the more typical words. This is the same pattern seen when errors are artificially elicited in the lab, with greater auditory activity for errors. Second, the participants with the greatest auditory responses also showed the largest corrective "centering" movements in their speech output. That is, the neural response to the sound of the voice while speaking predicted how much the error-like sounds were corrected (Fig. 2B).
These findings suggest that less-typical utterances, which make up a large proportion of natural speech, are processed in the brain as potential errors, and that speech error correction is occurring constantly on a small scale. How we process the sound of our own voice, in part, drives our speech movements to be more accurate.