Popular version of paper 3pAA4 Presented Wednesday afternoon, December 4, 2019 178th ASA Meeting, San Diego, CA
A former oil boomtown, El Dorado, Arkansas has a rich history, unique historic architecture, and a well-established arts and entertainment community, which includes the South Arkansas Symphony Orchestra, the South Arkansas Arts Center, and numerous successful music festivals. Community leaders sought to develop these assets into a regional draw and community anchor. The intent is to improve the quality of life and re-brand the community as a cultural performance mecca, while also slowing the decline in population (currently at 18,500) and revitalizing the local economy.
DLR Group’s master plan and design leverages existing historic assets, including the National Register-listed Griffin Auto Building, five other legacy structures, and new construction, to create a multi-venue downtown arts and entertainment district that preserves and celebrates the unique identity of El Dorado while appealing to contemporary audiences and future generations.
Implemented in phases, the project encompasses a 125,868 SF site and comprises a 7,000-patron festival venue/amphitheater, a 2,000-seat indoor music venue, a 100-seat black box/multi-purpose room, an 850-seat multi-use theater, a restaurant/club with stage, a visual arts facility, a farmers’ market, a children’s activity center, a park, and considerable site improvements for festivals along with new structures to support that use.
Phase 1 transformed the historic Griffin Auto Building (two-level, historic filling station, automotive showroom/repair shop) into a restaurant and flat-floor, indoor music venue. The warehouse was converted to an 1,800 seat (2,400 max. standing capacity) music venue.
Controlling the reverberation time, the time it takes sound to decay 60 decibels in a space, was critical to the acoustical success of the music venue. At over 18,000 square feet of floor space and nearly 600,000 cubic feet of volume, and constructed of concrete, metal deck, and masonry walls, the existing warehouse reverberation time was over 10 seconds long.
With a desired program of top tier modern amplified shows including rock and roll, country, and comedic talent, plus the South Arkansas Symphony Orchestra, the design goal for the renovated warehouse was 1.5 seconds in reverberation time.
Achieving this goal required ample use of acoustically absorptive material. After renovations to ensure the structural integrity of the existing roof were completed, and fireproofing was applied, 75% of the 30-foot-high and 96-foot-wide barrel-vaulted ceiling was covered with four-inch-thick fabric wrapped fiberglass panels. On lower walls, perforated metal panels were used for impact protection with fiberglass insulation behind for acoustical absorption. A total of almost 20,000 square feet of acoustically absorptive material was added to the warehouse.
File missing (1-RTGraph.jpg) Figure 1 – Reverberation time calculation comparison of the existing and proposed treated Warehouse
The open-air filling station was enclosed by a glass curtain wall and converted to a restaurant dining area with stage for performance of live music. Separating the two music venues, the showroom was partly converted to a commercial kitchen to serve the restaurant dining area, and partly converted to a VIP area for events.
Figure 2 – Photo of Historic Filing Station, circa 1928
Figure 3 – Photo of pre-renovation Filing Station used as covered parking in 2014
Figure 4 – Photo of post-renovation Filing Station used as a Restaurant in 2019
Figure 5 – Photo of Historic Warehouse Floor, circa 1928
Figure 6 – Photo of pre-renovation Warehouse floor in 2014
Figure 7 – Photo of post-renovation Warehouse floor and stage used as a music venue in 2019
Figure 8 – Photo of post-renovation Warehouse Floor used as a music venue in 2019 with seats
Popular version of paper 3pSC10 “Fearless Steps: Taking the Next Step towards Advanced Speech Technology for Naturalistic Audio” To be Presented between, Dec 2-6, 2019, 178th ASA Meeting, San Diego
J.H.L. Hansen, A. Joglekar, A. Sangwan, L. Kaushik, C. Yu, M.M.C. Shekhar, “Fearless Steps: Taking the Next Step towards Advanced Speech Technology for Naturalistic Audio,” 178th Acoustical Society of America, Session: 3pSC12, (Wed., 1:00pm-4:00pm; Dec. 4, 2019), San Diego, CA, Dec. 2-6, 2019.
NASA’s Apollo program represents one of the greatest achievements of humankind in the 20th century. During a span of 4 years (from 1968 to 1972), nine lunar missions were launched with 12 astronauts who walked on the surface of the moon. To monitor and assess this massive team challenge, all communications between NASA personnel and astronauts were recorded on 30-track 1-inch analog audio tapes. NASA recorded this in order to be able to review and determine best practices to improve success in subsequent Apollo missions. This analog audio collection essentially was set aside when the Apollo program was completed with Apollo-17, and all tapes stored in NASA’s tape archive. Clearly there are opportunities for research on this audio for both technology and historical purposes. The entire Apollo mission consists of well over ~150,000 hours. Through the Fearless Steps initiative, CRSS-UTDallas digitized 19,000 hours of audio data from Apollo missions: A-1, A-11 and A-13. The focus of this current effort is to contribute to the development of Spoken Language Technology based algorithms to analyze and understand various aspects of conversational speech. To achieve this goal, a new 30-track analog audio decoder was designed using NASA Soundscriber.
Figure 1: (left): The SoundScriber device used to decode 30 track analog tapes, and (right): The UTD-CRSS designed read-head decoder retrofitted to the SoundScriber [5]
To develop efficient speech technologies towards analyzing conversations and interactions, multiple sources of data such as interviews, flight journals, debriefs, and other text sources along with videos were used [8, 12, 13]. This initial research direction allowed CRSS-UTDallas to develop document linking and web application called ‘Explore Apollo’ wherein a user can access certain moments/stories in the Apollo-11 mission. Tools such as the exploreapollo.org enable us to display our findings in an interactive manner [10, 14]. A case in point is to illustrate team communication dynamics via a chord diagram. This diagram (Figure 2 (right)) illustrates the amount of conversation each astronaut has with each other during the mission, and the communication interactions with the capsule communicator (only personnel directly communicating with the astronauts). Analyses such as these provide an interesting insight into the interaction dynamics for astronauts in deep space.
Figure 2: (left): Explore Apollo Online Platform [14] and (right): Chord Diagram of Astronauts’ Conversations [9]
With a massive aggregated data, CRSS-UTDallas sought to explore the problem of automatic speech understanding using algorithmic strategies to answer the questions: (1) when were they talking; (2) who was talking; (3) what was being said; and (4) how were they talking. These questions formulated in technical terminologies are represented as the following tasks: (1) Speech Activity Detection [5], (2) Speaker Identification, (3) Automatic Speech Recognition and Speaker Diarization [6], (4) Sentiment and Topic Understanding [7].
The general task of recognizing what was being said at what time is called the “Diarization pipeline”. In an effort to answer these questions, CRSS-UTDallas developed solutions for automated diarization and transcript generation using Deep Learning strategies for speech recognition along with Apollo mission specific language models [9]. We further developed algorithms which would help answer the other questions including detecting speech activity, and speaker identity for segments of the corpus [6, 8].
Figure 3: Illustration of the Apollo Transcripts using the Transcriber tool
These transcripts allow us to search through the 19,000 hours of data to find keywords, phrases, or any other points on interest in a matter of seconds as opposed to listening to the audio for hours to search for the answers [10, 11]. The transcripts along with the complete Apollo-11 and Apollo-13 corpora are now freely available on the website fearlesssteps.exploreapollo.org
Audio: Air-to-ground communication during the Apollo-11 Mission
Figure 4: The Fearless Steps Challenge website
Phase one of the Fearless Steps Challenge [15] involved performing five challenge tasks on 100 hours of time and mission critical audio out of the 19,000 hours of the Apollo 11 mission. The five challenge tasks are:
Speech Activity Detection
Speaker Identification
Automatic Speech Recognition
Speaker Diarization
Sentiment detection.
The goal of this Challenge was to evaluate the performance of state-of-the-art speech and language systems for large task oriented teams with naturalistic audio in challenging environments. In the future, we aim to digitize all of the Apollo missions and make it publicly available.
A. Sangwan, L. Kaushik, C. Yu, J. H. L. Hansen and Douglas W. Oard. ”Houston, we have a solution: using NASA Apollo program to advance speech and language processing technology.” INTERSPEECH. 2013. C. Yu, J. H. L. Hansen, and Douglas W. Oard. “`Houston, We Have a Solution’: A Case Study of the Analysis of Astronaut Speech During NASA Apollo 11 for Long-Term Speaker Modeling,” INTERSPEECH. 2014. Douglas W. Oard, J. H. L. Hansen, A. Sangwan, B. Toth, L. Kaushik, and C. Yu. “Toward Access to Multi-Perspective Archival Spoken Word Content.” In Digital Libraries: Knowledge, Information, and Data in an Open Access Society, 10075:77–82. Cham: Springer International Publishing, 2016. A. Ziaei, L. Kaushik, A. Sangwan, J. H.L. Hansen, & D. W. Oard, (2014). “Speech activity detection for NASA Apollo Space Missions: Challenges and Solutions.” (pp. 1544-1548) INTERSPEECH. 2013. L. Kaushik, A. Sangwan, and J. H.L. Hansen. “Multi-Channel Apollo Mission Speech Transcripts Calibration,” 2799–2803. IINERSPEECH, 2017. C. Yu and J. H. L. Hansen, “Active Learning Based Constrained Clustering For Speaker Diarization,” in IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 25, no. 11, pp. 2188-2198, Nov. 2017. doi: 10.1109/TASLP.2017.2747097 L. Kaushik, A. Sangwan and J. H. L. Hansen, “Automatic Sentiment Detection in Naturalistic Audio,” in IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 25, no. 8, pp. 1668-1679, Aug. 2017. C. Yu, and J. H. L. Hansen. ”A study of voice production characteristics of astronaut speech during Apollo 11 for speaker modeling in space.” Journal of the Acoustic Society of America (JASA), 2017 Mar: 141(3):1605. L. Kaushik. “Conversational Speech Understanding in highly Naturalistic Audio Streams” PhD Dissertation, The University of Texas at Dallas, 2017. A. Joglekar, C. Yu, L. Kaushik, A. Sangwan, J. H. L. Hansen, “Fearless Steps Corpus: A Review Of The Audio Corpus For Apollo-11 Space Mission And Associated Challenge Tasks” In NASA Human Research Program Investigators’ Workshop (HRP), 2018. L. Kaushik, A. Sangwan, J. H. L. Hansen, “Apollo Archive Explorer: An Online Tool To Explore And Study Space Missions” In NASA Human Research Program Investigators’ Workshop (HRP), 2017. Apollo 11 Mission Overview: https://www.nasa.gov/-mission_pages/apollo/missions/apollo11.html Apollo 11 Mission Reports: https://www.hq.nasa.gov/alsj/a11-/a11mr.html Explore Apollo Document Linking Application: https://app.-exploreapollo.org/ Hansen, J. H., Joglekar, A., Shekar, M. C., Kothapally, V., Yu, C., Kaushik, L., & Sangwan, A. (2019). The 2019 inaugural fearless steps challenge: A giant leap for naturalistic audio. In Proc. Interspeech (Vol. 2019).
Jo M. Solet Joanne_Solet@HMS.Harvard.edu Harvard Medical School and Cambridge Health Alliance Assistant Professor of Medicine 15 Berkeley St, Cambridge, MA 02138 617 461 9006
Bonnie Schnitta bonnie@soundsense.com SoundSense, LLC Founder and CEO PO Box 1360, 39 Industrial Road, Wainscott, NY 11975 631 537 4220
Popular version of paper 2aNSa2 Presented Tuesday morning, December 3, 2019 178th ASA Meeting, San Diego, CA
As transportation noise continues to rise, social justice issues are being raised over the impacts on sleep, health, safety and well being.
The Federal Government, through the Federal Aviation Administration (FAA), is solely responsible for managing the National Airspace System, including flight paths and altitudes. The development of satellite based GPS “air navigation” or RNAV, introduced as a replacement for ground-based radar tracking, has allowed for flights at lower altitudes and at closer time intervals. It has also led to a consolidation of formerly more disbursed flight paths, producing a “super-highway” of flights over defined areas. The resulting noise levels impact concentration, communication and learning during the day and disrupt sleep at night.
Efforts to track and to force disbursal of these consolidated flight paths is underway. However, the government mandated statistics made available to the public, including day/night sound pressure level averages, fail to illuminate the peak exposure levels and timing. Additionally, statistics are reported in A-weighted metrics only, which deemphasizes low frequency sound components.
Some airports offer a “noise complaint hotline”. At Logan Airport in Boston, this hotline is not manned by a living person at night. Complainants may receive a letter several weeks after their call registering the receipt and content of the complaint. However, gauging noise impact levels by timing and/or number of complaints has serious flaws. Among these, sleep scientists are aware that subjects aroused from sleep by noise do not have full memory systems up and running. By morning, residents may be aware of having slept poorly, but be unable to report what aroused them or how often. The documented effects of inadequate sleep include increased likelihood of crashes, industrial accidents, falls, inflammation, pain, weight gain, diabetes and heart disease. Sleep disruption by noise is not simply “annoyance”.
Breakthrough research from Harvard Medical School sleep scientists, Jo M. Solet, Orfeu M. Buxton, and colleagues, quantified arousals from sleep by administering a series of noise source recordings at rising decibels to subjects in the sleep lab. This work demonstrated individual differences among sleepers as well as enhanced protection from arousal by noise in the deepest stages of sleep. Deep sleep is known to decrease dramatically with age; ours is an aging population.
There is now also preliminary evidence though the work of medical doctor, Carter Sigmon, and acoustical engineering leader, Bonnie Schnitta, suggesting that certain diagnoses, for example, PTSD, low thyroid function, and atrial fibrillation, carry extra vulnerabilities to noise exposure.
Acoustics experts, sleep scientists and public health advocates are working to inform policy change to protect our residents. This year two bills have been filed to require a National Academy of Medicine Consensus Report: HR 976, Air Traffic Noise and Pollution Expert Consensus Act by Congressman Stephen Lynch, and S2506, A Bill to Require a Study on the Health Impacts of Air Traffic Noise and Pollution by Senator Elizabeth Warren, both from Massachusetts.
Introduction Self-driving cars are currently a major interest for engineers around the globe. They incorporate more advanced versions of steering and acceleration control found in many of today’s cars. Cameras, radars, and lidars (light detection and ranging) are frequently used to detect obstacles and automatically brake to avoid collision. Air bags, which have been in use as early as 1951, soften the impact during an actual collision.
Vision Zero, an ongoing multinational effort, hopes that all car crashes will eventually be eliminated, and self-driving autonomous vehicles are likely to play a key role in achieving this. However, current technology is unlikely to be enough, as it does not works poorly in low light conditions. We believe that using sound, although it provides less which carries a unique information, is also important as it can be used in all scenarios and also likely performs much better.
Sound waves travel as fast as seventeen times faster in a car than at 1/3 of a kilometer per second in the air, which leads to much faster detection by using sound instead of acceleration, and clearly is not affected by light, air quality, and other factors. Previous research was able to use sound to detect collisions and sirens, but by the time a collision occurs, it is far too late. So instead we want to identify sounds that frequently occur before car crashes, such as tire skidding, honking, and sometimes screaming to figure out the direction they are coming from. Thus, we have designed a method to predict a car crash by detecting and isolating the sounds of tire skidding that might signal a possible crash.
Algorithm The algorithm utilizes the discrete wavelet transform (DWT), which decomposes a sound wave into high- and low-frequency components in time all sorts of tiny waves each lasting for a short period in time. This can be done repeatedly, yielding a series of components of various frequencies. Using wavelets is significantly faster and gives much more accurate and precise results representation of transient events associated with car crashes than elementary techniques such as the Fourier Transform, which transforms a sound into its frequency steady oscillation components. Previous methods to detect car crashes examined the highest frequency components, but tire skidding only contains lower frequency components, whereas a collision contains almost all frequencies.
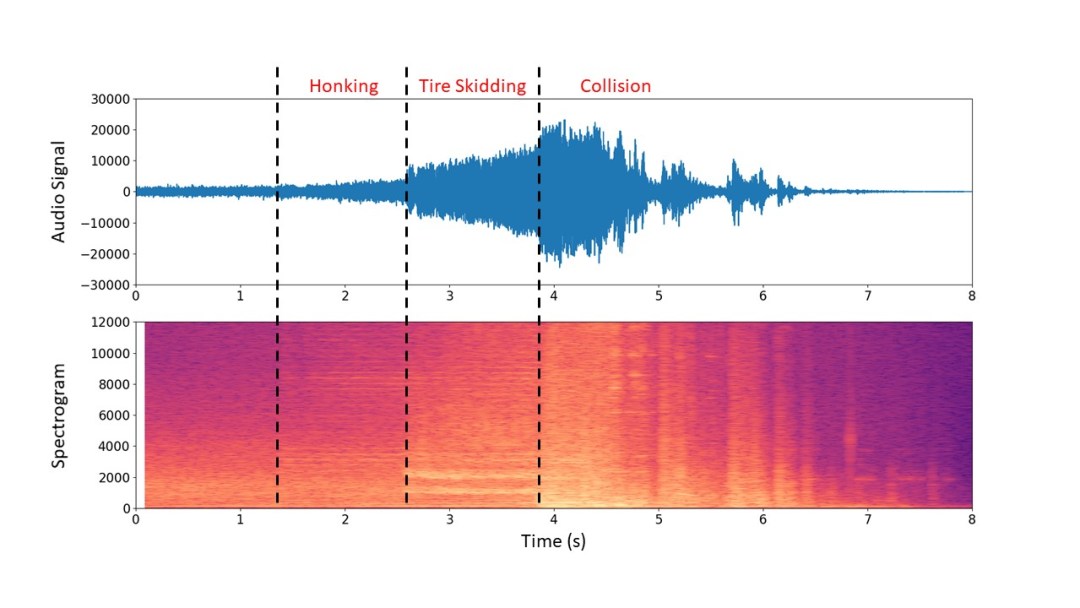
One can hear in the original audio of a car crash the three distinct sections: honking, tire skidding, and the collision.
The top diagram shows the audio displayed as a waveform, plotted against time. The bottom shows a spectrogram of the audio, with frequency on the y-vertical axis and time on the horizontal x-axis, and the brightness of the color representing the magnitude of a particular frequency component. This was created using a variation of the Fourier Transform. One can observe the differences in appearance between honking, tire skidding, and collision, which suggests that mathematical methods should be able to detect and isolate these. We can also see that the collision occupies all frequencies while tire skidding occupies lower frequencies with two distinct sharp bands at around 2000Hz.
“OutCollision.wav , the isolated audio containing just that isolates the car crash”
Using our algorithm, we were able to create audio files containing just that isolate the honking, tire skidding, as well as the collision. One can hear that they doThey may not sound like normal honking, tire skidding or collisions, which is a byproduct of our algorithm. Fortunately, but this does not affect the ability to detect the tire skidding various events by a computer.
Conclusion The algorithm performs well for detecting the honking and tire skidding, and is fast enough to be done in real time, before acceleration information can be processed which would be great for the raising the alert of a possible crash, and for activating the hazard lights and seatbelt pre-tensioners. The use of sound in cars is a big step forward for the analysis prevention of car crashes, as well as improving autonomous and driverless vehicles and achieving Vision Zero, by providing a car with more timely and valuable information about its surroundings.
Gaëtan Richard – gaetan.richard@ensta-bretagne.fr Flore Samaran – flore.samaran@ensta-bretagne.fr ENSTA Bretagne, Lab-STICC UMR 6285 2 rue François Verny 29806 Brest Cedex 9, France
Julien Bonnel – jbonnel@whoi.edu Woods Hole Oceanographic Institution 266 Woods Hole Rd Woods Hole, MA 02543-1050, USA
Christophe Guinet – christophe.guinet@cebc-cnrs.fr Centre d’Études Biologiques de Chizé, UMR 7372 – CNRS & Université de La Rochelle, 79360 Villiers-en-Bois, France
Popular version of paper Presented Wednesday afternoon, December 4, 2019 178th ASA Meeting, San Diego, CA
Toothed whales feeding on fish caught on longlines is a growing issue worldwide. This issue named depredation has a serious socio-economic impact and raise conservation questions. Costs for fishermen include damages to the fishing gear and increased fishing effort to complete quotas. For marine predators, depredation increases risks of mortality (lethal retaliation from fishers or bycatch on the gear) and behavior changes, with a loss of natural foraging behavior for an easy human-related food source. Most of studies assessing depredation by odontocetes on longline fisheries have primarily relied on surface observation performed from the fishing vessels during the hauling phase (i.e. when gears are retrieved on board). The way odontocetes interact with longlines underwater thus remains poorly known. In particular, depredation by odontocetes on demersal longlines (i.e. lines that are set on the seafloor) has always been considered to occur only during hauling phases, when the fish are pulled up from the bottom to the predators at the surface.
Figure 1
In our study, we focused on the depredation by killer whales on a demersal longline fisheries around Crozet Archipelago (Southern Ocean, Figure 1). Here, we aimed at understanding how, when and where interactions really occur. Recent studies revealed that killer whales could dive up to 1000 m, suggesting that they can actually depredate on longlines that are set on seafloor (remember that the traditional hypothesis was that depredation occurs only during hauling, i.e. close from the sea surface when the lines are brought back to the ship). In order to observe what can’t be seen, we used hydrophones to record sounds of killer whales, fixed on the fishing gears (Figure 2). This species is known to produce vocalization to communicate but also echolocation clicks as a sonar to estimate the direction and the range of an object or a prey (Figure 3). Altogether, communication and echolocation sounds can be used as clues of both presence and behaviour of these toothed whales. Additionally, as killer whales also sense the environment by listening to ambient sounds, we recorded the sounds produced by the fishing vessels, in order to understand more how these predators can detect and localize the fishing activities.
Figure 2. Scheme of fishing phases (setting, soaking and hauling) with the hydrophone deployed on a longline.
Figure 3. Spectrogram of killer whales’ sounds recorded around a fishing gear. This figure is a visual representation of the variation of intensities (color palette) of frequencies of sounds as they vary with time. On the recording we observe both calls (communication sounds) and clicks of echolocation, which can be heard as ‘buzzes’ when the emission rate is too fast to dissociate each click. Click image to listen.
Our main result is that killer whales were present and probably looking for food (production of echolocation clicks) around the longline equipped with the hydrophone while the boat was not hauling or too far to be interacting with the whales. This observation strongly suggest that depredation occurs on soaking longlines, which contradict the historical hypothesis that depredation only occurs during the hauling phases when the behavior is most easily observed from the fishing vessels. However, this new results raises the question on how killer whales know where to find the longlines in the ocean immensity. However, we also observed that the fishing vessels produced different sounds between the setting of longlines and their hauling (Figure 4). We therefore hypothesize that killer whales are able to recognize and to localize the vessel activity using the ship noise, allowing them to find the longlines.
Figure 4. Spectrograms of a fishing vessel setting a longline (left panel) and maneuvering during hauling (right panel). On the first spectrogram, we observed a difference of sound intensity between the setting (until 38 s) and the post setting, while the vessel was still moving forward (after 38 s). On the second spectrogram we recorded a vessel going backwards while hauling the longline, such maneuver characterize the activity and increase the range that killer whale can detect the fishing vessel.
Goldie Phillips – gphillips@sci-brid.com Sci-Brid International Consulting, LLC 16192 Coastal Hwy Lewes, DE 19958
Gerald D’Spain – gdspain@ucsd.edu Catalina López-Sagástegui – catalina@ucr.edu Octavio Aburto-Oropeza – maburto@ucsd.edu Dennis Rimington – drimington@ucsd.edu Dave Price – dvprice@ucsd.edu Scripps Institution of Oceanography, University of California, San Diego 9500 Gilman Drive San Diego, CA 92093
Miguel Angel Cisneros-Mata – macisne@yahoo.com Daniel Guevara – danyguevara47@hotmail.com Instituto Nacional de Pesca y Acuacultura (INAPESCA) Mexico Del Carmen, Coyoacán 04100 Mexico City, CDMX, Mexico
Popular version of paper 2pAB Presented Tuesday afternoon, December 3rd, 2019 178th ASA Meeting, San Diego, CA
The totoaba (Figure 1), the largest fish of the croaker family, faces a severe illegal fishing threat due largely to the high value of its swim bladder (or buche; Figure 2) in Asian markets. While several conservation measures have been implemented in the Gulf of California (GoC) to protect this endemic species, the totoaba’s current population status remains unknown. Passive acoustic monitoring (PAM) – the use of underwater microphones (called hydrophones) to detect, monitor, and localize sounds produced by soniferous species – offers a powerful means of addressing this problem.
Croaker fishes are well known for their ability to produce sound. Their characteristic “croaking” sound is produced by the vibration of their swim bladder membrane caused by the rapid contraction and expansion of nearby sonic muscles. As sound propagates very efficiently underwater, croaks and other sounds produced by species like the totoaba can be readily detected and recorded by specialized PAM systems.
However, as little is known about the characteristics of totoaba sounds, it is necessary to first gain an understanding of the acoustic behavior of this species before PAM can be applied to the GoC totoaba population. Here we present the first step in a multinational effort to implement such a system.
Figure 1. Totoaba housed at CREMES
Figure 2. Totoaba swim bladder.
We conducted a passive acoustic experiment at the aquaculture center, El Centro Reproductor de Especies Marinas (CREMES), located in Kino Bay, Mexico, between April 29 and May 4, 2019. We collected video and acoustic recordings from totoaba of multiple age classes, both in isolation and within group settings. These recordings were collectively used to characterize the sounds of the totoaba.
We found that in addition to croaks (Video 1) captive totoaba produce 4 other call types, ranging from short duration (<0.03s), low-frequency (<1kHz) narrowband pulses, classified here as “knocks” (Video 2), to longer duration, broadband clicks with significant energy over 10kHz. There is also indication that one of the remaining call types may function as an alarm or distress call. Furthermore, call rates and dominant call type were found to be dependent on age.
Video 1. Visual representation (spectrogram) of a croak produced by totoaba at CREMES. Time (in minutes and seconds) is shown on the x-axis with frequency (in kHz) displayed on the y-axis. Sounds with the greatest amplitude are indicated by warmer colors.
Video 2. Visual representation (spectrogram) of a series of “knocks” produced by totoaba at CREMES.
As PAM systems typically produce large amounts of data that can make manual detections by a human analyst extremely time-consuming, we also used several of the totoaba call types to develop and evaluate multiple automated pre-processing/detector algorithms for a future PAM system in the GoC. Collectively, results are intended to form the basis of a totoaba population assessment that spans multiple spatial and temporal scales.