
Clifford F. Lewis- clewis@gwis.com
Stephen B. Fountain
Dept. of Psych., Kent State University
P.O. Box 5190
Kent, OH 44242-0001
Michael K. McBeath
Dept. of Psych., Arizona State University
Tempe, AZ 85287-1104
Note: First author can be reached at (216) 371-3981
Popular version of paper 4pPP3
Presented Thursday afternoon, November 4, 1999
138th ASA Meeting, Columbus, Ohio
A neural network model can provide a possible explanation for virtual pitch. Also known as the missing fundamental, virtual pitch is one of the classic phenomena in auditory perception. The model demonstrates that the harmonics of complex tones form recognizable patterns, and it suggests that the brain may fill in missing parts of those patterns to create perceptions of virtual pitch.
Virtual pitch presents an intriguing problem in understanding how people perceive the pitch of musical notes. Virtual pitch, or the missing fundamental, refers to the fact that if the fundamental frequency is filtered out of a complex sound, the perceived pitch usually does not change. The lowest harmonic is now twice the fundamental, which is the same frequency as the fundamental for a note an octave higher. In many ways, however, the missing fundamental still is more similar to the lower note than it is to the higher. For example, an A2 has a fundamental frequency of 110 Hz, with harmonics at 220, 330, 440, 550, etc. An A3, an octave above, has a fundamental of 220 Hz, with harmonics at 440, 660, 880, etc. Without the fundamental, the lowest harmonic in an A2 is 220 Hz, but the odd harmonics at 330, 550, etc. are still present. Given this combination of harmonics, people perceive hearing the 110 Hz fundamental. This seems counterintuitive, in that a person would perceive hearing the fundamental frequency when it isnt there.
One well-accepted theory of pitch perception is the place coding theory. According to this theory, portions of the basilar membrane of the inner ear are tuned to respond to different frequencies, with the vibrations occurring close to the entrance of the inner ear for high-frequency sounds, and farther away for low-frequency sounds. Neural receptors in the inner ear detect these vibrations, and the perceived pitch is determined by what position on the basilar membrane is vibrating the most. This model cannot by itself explain virtual pitch, however, because there is no sound energy to cause the basilar membrane to vibrate at the low-frequency position.
Most of these models are still much too simple to be regarded as realistic models of brain functions. However, they do often yield results that are suggestive of brain characteristics. They excel at making associations and identifying patterns. Their abilities to learn and to respond to stimuli are not constrained to the strict logic of a computer program. They show an ability to adapt to changes, and to recognize degraded or modified inputs.
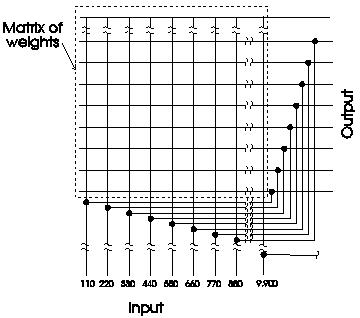
The network was "trained" using harmonic data for a variety of musical instruments. All of the A notes from A2 to A6 were used in training. Each input of the network corresponded to the intensity of one harmonic, with a total of 90 inputs. The network was trained by repeatedly inputting the harmonics of each instrument one at a time until the difference between input and output was small for the last instrument in the set.
For the test part of the experiment, the network was given the same inputs as in the training phase, but with zeros as input for the fundamental frequency of each note.
The neural network model compensated for the missing fundamental, filling in the missing part of the pattern and producing an output that was very similar to the output produced when the fundamental was present. Even the output corresponding to the fundamental showed a significant activation.
If our brains have a similar ability to make associations between harmonics, then this model of pitch coding can explain the problem of virtual pitch. From the time we are born, and even before, we hear sounds that are rich in harmonics. Most of the time, the same harmonics are present for a given pitch, regardless of the sound source. The network model demonstrates that it is possible even for a simple network to learn to associate these co-occurring frequencies with each other. A missing fundamental (or any other missing harmonic) results in a degraded input. The network model recognizes the partial input and simply fills in the missing parts.
The model helps explain why low-quality sound systems, such as telephones, still produce satisfactory sounds even when low and high frequencies are not reproduced. It also helps explain why people with minor hearing losses do not notice their losses. According to this model, we dont notice the missing harmonics because our brains can fill in the missing parts, given a sufficient match to the harmonics that are present.
| Type | Note | ||||||||
| input | a2 |
0.537
|
0.5994
|
0.3502
|
0.3676
|
0.3701
|
0.2748
|
0.3002
|
0.1801
|
| output | a2 |
0.3153
|
0.5362
|
0.3108
|
0.3726
|
0.3221
|
0.2723
|
0.3189
|
0.1734
|
| missfund | a2 |
0.3153
|
0.1535
|
0.2052
|
0.3738
|
0.3524
|
0.3808
|
0.2604
|
0.1607
|
| input | a3 |
0
|
0.6568
|
0
|
0.5297
|
0
|
0.3815
|
0
|
0.1908
|
| output | a3 |
0.0372
|
0.3367
|
0.0216
|
0.4611
|
0.028
|
0.3362
|
-0.0162
|
0.1704
|
| missfund | a3 |
-0.0619
|
0.3367
|
-0.0255
|
0.3872
|
0.0397
|
0.2421
|
4E-05
|
0.1847
|
| input | a4 |
0
|
0
|
0
|
0.8349
|
0
|
0
|
0
|
0.4595
|
| output | a4 |
0.0208
|
-0.0032
|
0.0011
|
0.5229
|
0.0028
|
0.061
|
0.006
|
0.3965
|
| missfund | a4 |
0.0373
|
-0.0692
|
-0.0098
|
0.5229
|
-0.0205
|
-0.0227
|
0.029
|
0.2576
|
| input | a5 |
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0.849
|
| output | a5 |
-0.0076
|
-0.0217
|
0.0076
|
0.1108
|
0.0019
|
0.0227
|
-0.0041
|
0.3968
|
| missfund | a5 |
-0.0146
|
0.0168
|
-0.0126
|
-0.0777
|
-0.0114
|
-0.0301
|
-0.0108
|
0.3968
|
| input | a6 |
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
| output | a6 |
0.0214
|
0.0856
|
-0.0074
|
-0.0897
|
0.0118
|
0.0025
|
-0.0155
|
0.4005
|
| missfund | a6 |
0.0749
|
-0.0655
|
0.0414
|
-0.0287
|
0.0092
|
-0.0166
|
0.0024
|
-0.0257
|