
Popular version of paper 4aSC10
Presented Friday morning, June 2, 2000
139th ASA Meeting, Atlanta, Georgia
For additional information, please contact Dilys Jones at (213)
353-7012
A version of this work has been submitted to Academic Press for possible publication. Copyright may be transferred without notice, after which this version may no longer be accessible
Abstract
The capacity to understand speech from the moving lips of a talker
(lipreading) is thought to be extremely difficult. Popular imagery
has typically represented lipreading as a result of very complex computations
(e.g., the super-computer Hal in "2001: A Space Odyssey"). In our research,
we found that, despite the impoverishment of visual speech compared to
auditory speech, it is possible to predict which words will be recognized
most accurately, based on computational estimates of words' visual distinctiveness
from the other words of the dictionary. Specifically, we predicted that
words that are visually distinct from all other words should be identified
almost as well as their auditory counterparts. This is exactly what we
found. Moreover, deaf and hearing participants performed in very similar
ways. The results demonstrate that: (1) lipreading is more predictable
than it is thought to be, (2) lipreading can be very accurate for words
that are visually distinct from other words, and (3) lipreading shows strong
similarities with the mechanisms involved in the recognition of auditory
words.
Visual Similarity of Speech Sounds and Assistance from the Lexicon
Below is an illustration of the problem that lipreaders face when they
try to recognize words from moving lips. Visually, the words "bat" and
"pat" are highly similar. This is so because the articulatory gestures
that distinguish the speech categories (or phonemes) "B" and "P"
take place in a location of the vocal tract hidden from view: the vocal
cords. To produce the phonemes "B" and "P", the lips come together and
come apart suddenly. The vocal cords have to vibrate at the same time for
"B", but are delayed for "P".

|

|
|
|
|
However, the problem of similar appearing phonemes can be solved for
many words in our vocabulary (or mental lexicon). For example, the
confusion between "B" and "P" illustrated above is unlikely to happen when
the word "brief" is spoken, because a word like "prief" does not exist
in the lexicon. Thus, the content of the lexicon can dramatically reduce
the problem of visual impoverishment that occurs for visual speech.

|
|
|
Experiment
In this study, we showed that visual word recognition accuracy can be predicted based on (1) phoneme similarity estimates, and (2) an approximation of the content of the American English lexicon.
Participants.
Eight individuals with profound hearing impairements
(deaf) and eight individuals with normal hearing
were tested. All were undergraduate students of the California State University
at Northridge. Mean age was 22.5 years (range: 19 to 26) for the deaf group
-- onset of hearing impairements was pre-lingual -- and 23.5 years (range:
21 to 28) for the hearing group. All of the participants were good or better
lipreaders.
Experimental Procedure.
Participants were seated in front of a computer monitor in a quiet
room. 282 words, presented one at a time, were spoken by a female talker,
with her face filling most of the monitor frame. The sound was turned off.
The participants' task was to identify each word the talker said by typing
it in on a computer keyboard. After entering a response, the participants
pressed a keyboard key to see the next word.
Stimuli.
Three types of words were presented, as a function of their similarity
with other words in the lexicon (i.e., the number of visual competitors).
- words with no visual competitors
UNIQUE
- words that are visually similar to 1 to 5 other words
MEDIUM
- words that are visually similar to 9 or more words
HIGH
The number of competitors was estimated based on computer modeling of the lexicon, which used data on visual confusions among consonant-vowel syllables ("ba", "da", "ta", etc.).
In addition, half the test words were chosen among frequently-occurring words (used daily in conversational English) and the other half among infrequently-occurring words. Words were also either one syllable long or two syllables long.
Results. Word recognition accuracy, in percent words correct, is shown in the graphs below, separately for the deaf and the hearing participants.
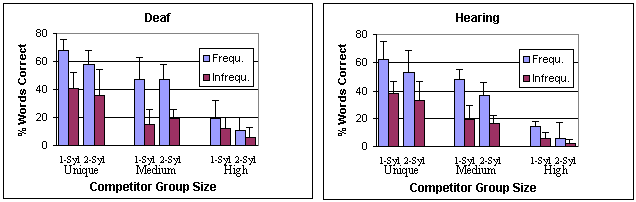
These graphs underscore several findings:
Conclusion
Lipreading is far more than a "guessing game": Visual word recognition depends on more than contextual information and strategic processes. This experiment shows that word lipreading is amenable to scientific investigation. Performance can be predicted based on computer analyses of the lexicon and of the typical patterns of phoneme similarity. For example, as predicted, several test words labeled as "unique" were identified correctly by all of the participants (e.g., brief, floor, special, question). In contrast, a majority of test words that were predicted to be similar to many other words were recognized only occasionally, or not at all (e.g., news, best, hidden, basic).
Likewise, the frequency of occurrence of the test words contributed to recognition accuracy. Independently of their number of visual competitors, frequent words were recognized more accurately than infrequent words.
Effects of lexical similarity and of frequency of occurrence are mechanisms
that have been observed repeatedly in the auditory word recognition domain.
The present results indicate that these two principles apply to "word recognition"
in general, regardless of the perceptual modality, regardless of the specific
patterns of phoneme similarity, and regardless of the hearing status of
the perceiver (deaf vs. hearing).
This work was supported by NIH Grant # DC02107.