[ Lay Language Paper Index | Press Room ]
Computing the Difference Between Speech and Song
David Gerhard - david.gerhard@uregina.ca
University of Regina
3737 Wascana Parkway
Regina, SK
CANADA S4S 0A2
Popular version of paper 4aSP5
Presented Thursday morning, November 13, 2003
146th ASA Meeting, Austin, TX
Introduction
Most people have no trouble identifying and distinguishing between the
sounds we hear. It is one of the abilities that allows us to
communicate, or to appreciate music. We instinctively move toward
a noisy baby but away from a noisy predator. Our ability to distinguish
between speaking and singing allows us to interpret each utterance in
its appropriate context, just as subtle speech inflections provide
emphasis and extra information. It is another story, however,
when we try to describe these differences objectively, in an attempt to
allow computers to perform this task as easily as we can. Ask a
person to identify a song hidden in a list of spoken phrases, and they
will have no difficulty. Ask a person to describe what makes
these differences, and the task is slightly harder.
This is a first step in developing computer models of the differences
between speech and song: finding the features
or characteristics that people identify as important. When
performing speech recognition, many researchers these days use a
collection of features based on energy at specific frequencies of the
sound signal. The benefit is that the features are standard, well
documented, and perform well, for the speech recognition
task. These features do not, however, fully characterise
all human utterances, and so a new set of features must be
developed.
Sound Files and Features
The features explored in this work are perceptual, meaning that they are
based on how people hear. To do this, the first step was to
gather a corpus, or
collection of sounds to test. These were gathered from interviews
using specific prompts, as well as from existing media. You can
listen to some sounds from the corpus on the web:
We collected examples of people speaking and singing the same text, so
that the only differences would be the characteristics of speech and
song that we were looking for. Some examples are presented here.
The next step was to have subjects listen to these samples and identify
the characteristics they thought were important to make the difference
between talking and singing. The experiment was available
on-line, and while the experiment is now over, some information and
examples are available on the web:
The main differences people mentioned were about pitch and
rhythm. Pitch differences included vibrato, pitch range, and
pitch on a musical scale. Rhythmic qualities were less well
defined– most people who mentioned rhythm didn’t specifically indicate
what made the difference, just that song was more rhythmic than speech.
Feature Models
When building the computer models, all of these characteristics were
taken into account, and a set of algorithms
or processes were
designed to extract this information from the sound wave. Each
process looked for a feature, like vibrato, within the sound signal and
assigned a number to that sound, based on the presence of that
feature. After these numbers were assigned, the corpus was
divided into talking files and singing files, and the statistical
distribution of the feature values was analysed for each feature, and
compared to produce the computer model of the feature. Some
examples are present in Figures 1-3:

Figure 1. Feature model of mean pitch
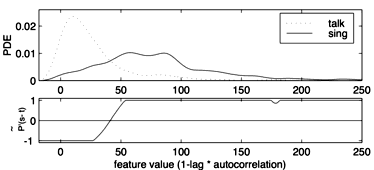
Figure 2. Feature model of vibrato, based on autocorrelation
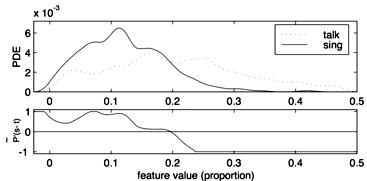
Figure 3. Feature model of proportion of voiced frames, based on
pitch
These figures show how talking files and singing files have different
distributions of their feature values. For example, looking at
the computer model for vibrato (Figure 2) we see that talking files
tend to have very little vibrato, while singing files tend to have
varied amounts of the feature. Because there is considerable
overlap where talking and
singing files can have the same value, these models by themselves will
not
be able to classify talking and singing files completely accurately,
but together they may do better.
Evaluating the Models
Once the models have been built, the next task is to evaluate
them. We want to make sure that:
- The models are measuring what we think they are measuring,
- The models can make a speech-song decision that is correct most
of the
time, and
- The models are not all measuring the same thing.
Point 3 is important because if the models were all measuring the same
thing, combining them would not improve the results, so we would not be
able to make any judgement when the talking and singing files have the
same feature value.
To evaluate the models, we allow them to make a decision and we compare
that with what we know about the sound. If the file contains
talking and the model agrees, it is considered correct. If the
model thinks that the file is singing instead, it is incorrect.
The models in this system range from 50% to 80% correct.
The next evaluation is to find out whether the models are measuring the
same thing or different things. To do this, we compare the
feature values for each file. If two models produce the same or
similar feature values for most of the corpus, then the chances are
good that these two features are actually measuring the same
thing. There are some models in this system that were discovered
to be measuring the same thing, and many that were measuring quite
different things.
Conclusions
What we have learned is that there are many different characteristics
that allow us to differentiate between speaking and singing, and that
it is possible to develop computer models to identify these
characteristics. A single characteristic is not sufficient to
make a reliable decision – many different characteristics must be
considered. The computational models used in this system are
based on the way we humans listen, and can be evaluated using
statistical techniques.
[ Lay Language Paper Index | Press Room ]
