
Katrin Kirchhoff - katrin@ee.washington.edu
Dept of Electrical Engineering
University of Washington
215E EE/CS Building, Box 352500
Seattle, WA, 98195
Popular version of paper 4pSC10
Presented Thursday Afternoon, Novermber 13, 2003
146th ASA Meeting, Austin, TX
"Loook! Look at the dooooggyyyy!" Caregivers' speech addressed to infants commonly takes on a hyperarticulated quality, marked by more pronounced pitch excursions and overemphasized phonetic contrasts compared to adult-directed speech. Previous studies (e.g. Couper and Aslin, 1994; Kuhl et al., 1997) have shown that such "motherese"-style speech occurs in a variety of languages and is preferred by infants over adult-directed speech. Presumably, the phonetic properties of motherese help infants acquire the sound system of their native language (Liu, Kuhl and Tsao, 2003).
It has been hypothesized that automatic speech recognizers might similarly benefit from training material consisting of hyperarticulated speech since the acoustic models formed during training might be more distinct. On the other hand, present-day speech recognizers are highly susceptible to mismatches between training and test data, casting doubt on the feasibility of this method.
We analyzed the performance of speech recognizers trained on adult-directed vs. infant directed speech and tested under identical vs. mismatched conditions. Training data was drawn from conversations between 32 mothers and their infants on the one hand and adult experiment facilitators on the other. Subjects were encouraged to use the same set of cue words (monosyllabic words like "boot,""shoe,""sheep," etc.) in both conversations, allowing a comparison of acoustic model performance without regard to word frequency effects.
Our experiments showed that isolated-word recognizers trained on matched conditions always obtained a better performance than those trained on mismatched conditions, showing that matched data is still of primary importance for high-quality automatic speech recognition. However, recognizers trained on infant-directed speech showed a more graceful degradation in performance when applied to adult-directed speech than vice versa. This suggests that the greater variability encountered in motherese-style training data leads to better generalization performance on unseen test cases.
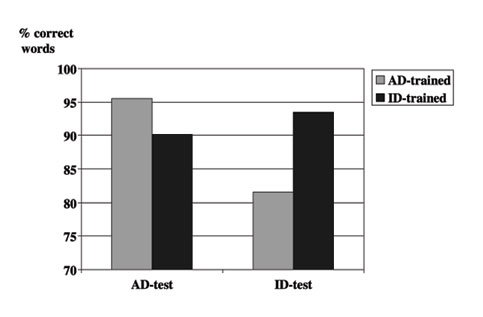
Percentage of correctly recognized words under different training and test conditions (AD = adult-directed, ID = infant-directed).
[Work supported by the Center for Mind, Brain and Learning, University of Washington]
References:
Cooper, R.P. and R.R. Aslin (1994) "Developmental differences in infant attention to the spectral properties of infant-directed speech", Child Development 6, 1663-1677
Kuhl, P. et al. (1997) "Cross-language analysis of phonetic units in language addressed to infants", Science 277, 684-686
Liu, H.-M., P. Kuhl and F.-M. Tsao (2003) "An association between mothers' speech clarity and infants' speech discrimination skills", Developmental Science 6:3, F1-F10