
Juergen Schroeter - jsh at research dot att dot com
AT&T Labs
Research, Room D163
180 Park Ave.
Florham Park, NJ 07932
Popular version of paper 1pSC5
Presented Monday afternoon, November 15, 2004
148th ASA Meeting, San Diego, CA
Summary
Text-to-Speech (TTS) has come a long way from being an essential tool for a
small group of important users, mainly for the handicapped, to delivering high
quality synthetic speech for many other applications, such as in voice-enabled
telecom services and on the desktop. Today's key TTS applications in communications
include: voice rendering of text-based messages such as email or fax as part
of a unified messaging solution, as well as voice rendering of visual/textual
information (e.g., web pages). In the more general case, TTS systems provide
voice output for all kinds of information stored in databases (e.g., phone numbers,
addresses, car navigation information) and information services (e.g., restaurant
locations and menus, movie guides, etc.). Ultimately, given an acceptable level
of speech quality, TTS could also be used for reading books (i.e., Talking Books)
and for voice access to large information stores such as encyclopedias, reference
books, law volumes, etc., plus many more. Today's much larger set of viable
applications for TTS technology is mainly due to the significant improvements
in naturalness of the synthetic speech that unit-selection synthesis has made
possible.
Speech Synthesis Methods
There exist several different methods to synthesize speech. Each method falls
into one of the following categories: articulatory synthesis, formant synthesis,
and concatenative synthesis [1].
Articulatory synthesis uses computational biomechanical models of speech production, such as models for the glottis (that generates the periodic and aspiration excitation) and the moving vocal tract. Ideally, an articulatory synthesizer would be controlled by simulated muscle actions of the articulators, such as the tongue, the lips, and the glottis. It would solve time-dependent, three-dimensional differential equations to compute the synthetic speech output. Unfortunately, besides having notoriously high computational requirements, articulatory synthesis also, at present, does not result in natural-sounding fluent speech (static vowels, for example, as well as vowel-to-vowel transitions, can be synthesized sounding "natural," but most stop consonants sound mediocre at best). Speech scientists still lack significant knowledge to achieve this somewhat elusive goal. More information can be found in [2].
Formant synthesis uses a set of rules for controlling a highly simplified source-filter model that assumes that the (glottal) source is completely independent from the filter (the vocal tract). The filter is determined by control parameters such as formant frequencies and bandwidths. Each formant is associated with a particular resonance (a "peak" in the filter characteristic) of the vocal tract. The source generates either stylized glottal or other pulses (for periodic sounds) or noise (for aspiration or frication). Formant synthesis generates highly intelligible, but not completely natural sounding speech. However, it has the advantage of a low memory footprint and only moderate computational requirements [3].
Concatenative synthesis uses actual snippets of recorded speech that were cut from recordings and stored in an inventory ("voice database"), either as "waveforms" (uncoded), or encoded by a suitable speech coding method. Elementary "units" (i.e., speech segments) are, for example, phones (a vowel or a consonant), or phone-to-phone
transitions ("diphones") that encompass the second half
of one phone plus the first half of the next phone (e.g., a vowel-to-consonant
transition). Some concatenative synthesizers use so-called demi-syllables (i.e.,
half-syllables; syllable-to-syllable transitions), in effect, applying the "diphone"
method to the time scale of syllables. Concatenative synthesis itself then strings
together (concatenates) units selected from the voice database, and, after optional
decoding, outputs the resulting speech signal. Because concatenative systems
use snippets of recorded speech, they have the highest potential for sounding
"natural." In order to understand why this goal was, until recently,
hard to achieve and what has changed in the last few years, we need to take
a closer look.
Concatenative TTS Systems
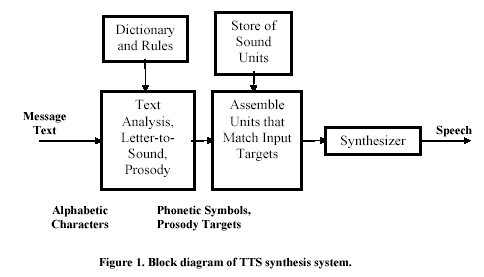
Figure 1. Block diagram of TTS synthesis system. Concatenative speech synthesis uses snippets (units) of recorded speech, usually cut from full sentences. Commonly employed units are diphones (bracketing exactly one phone-to-phone transition, starting from the spectrally stable middle region of one phone to the spectrally stable middle region of the next phone), or demisyllables (comprising consonants and vowels). At synthesis time, the unit inventory (voice database) is searched for the optimal sequence of units that make up the desired speech output [4].
A block diagram of a typical concatenative TTS system is shown in Fig. 1. The first block is the message text analysis module that takes ASCII message text and converts it to a series of phonetic symbols and prosody (fundamental frequency, duration, and amplitude) targets. The text analysis module actually consists of a series of modules with separate, but in many cases intertwined, functions. Input text is first analyzed and non-alphabetic symbols and abbreviations are expanded into full words. For example, in the sentence "Dr. Smith lives at 4305 Elm Dr.," the first "Dr." is transcribed as "Doctor," while the second one is transcribed as "Drive." Next, "4305" is expanded to "forty three oh five." Then, a syntactic parser (recognizing the part of speech for each word in the sentence) is used to label the text. One of the functions of syntax is to disambiguate the sentence constituent pieces in order to generate the correct string of phones, with the help of a pronunciation dictionary. Thus, for the above sentence, the verb "lives" is disambiguated from the (potential) noun "lives" (plural of "life"). If the dictionary look-up fails, general letter-to-sound rules are used. Finally, with punctuated text, syntactic and phonological information available, a prosody module predicts sentence phrasing and word accents and, from those, generates targets, for example, for fundamental frequency, phoneme duration, and amplitude. The second block in Fig. 1 assembles the units according to the list of targets set by the front-end. It is this block that is responsible for the innovation towards much more natural sounding synthetic speech. Then the selected units are fed into a back-end speech synthesizer that generates the speech waveform for presentation to the listener.
Recently, TTS systems have become much more natural sounding, mostly due to a wider acceptance of corpus-driven unit-selection synthesis paradigms. In a sense, the desire for more natural-sounding synthetic voices that is driving this work was a natural extension of the earlier desire to achieve high intelligibility. We have started a new era in synthesis, where, under certain conditions, listeners cannot say with certainty whether the speech they are listening to was recorded from a live talker, or is being synthesized. The new paradigm for achieving very high quality synthesis using large inventories of recorded speech units is called "unit-selection synthesis."
What is behind unit-selection synthesis and the corresponding sea change in voice quality it achieves? Many dimensions come to play. One important aspect is the ever-increasing power and storage capacity of computers. This has direct effect on the size of the voice inventory we can store and work with. Where early concatenative synthesizers used very few (mostly one) prototypical units for each class of inventory elements, we can now easily afford to store many such units. Other important aspects include the fact that efficient search techniques are now available that allow searching potentially millions of available sound units in real time for the optimal sequence that make up a target utterance. Finally, we now have automatic labelers that speed up labeling a voice database phonetically and prosodically. It is important to note that both, the automatic labelers and the optimal search strategies borrow heavily from speech recognition [5]. In the
following, we will briefly touch upon all relevant issues, after having reviewed "diphone synthesis."
From Diphone-Based Synthesis to Unit Selection Synthesis
For TTS, more powerful computers have a direct effect on the size of the voice
inventory we can store and work with. Early concatenative synthesizers (e.g.,
[1], [4], [6], [7][5]), used very few prototypical units for each class of inventory
elements, due to limitations in computational resources. These limitations resulted
in what we may consider a "low resolution" representation of the acoustic-phonetic
space that a speech synthesizer needs to cover. With a sparse representation
of the space, the problems of distortion and smoothness between concatenated
synthesis units become acute.
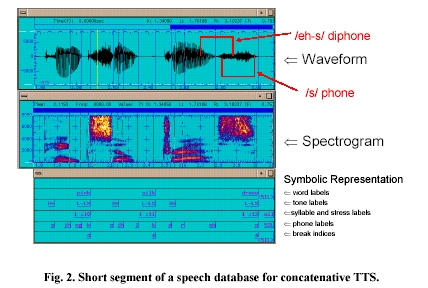
Any kind of concatenative synthesizer relies on high-quality recorded speech databases. An example fragment from such a database is shown in Fig. 2. The top panel shows the time waveform of the recorded speech signal, the middle panel shows the spectrogram ("voice print"), and the bottom panel shows the annotations that are needed to make the recorded speech useful for concatenative synthesis.
In the top panel of Fig. 2, we see the waveform for the words "pink silk
dress." For the last word, dress, we have bracketed the phone /s/ and the
diphone /eh-s/ that encompasses the latter half of the /eh/ and the first half
of the /s/ of the word "dress." For American English, a diphone-based
concatenative synthesizer has, at a minimum, about 1000 diphone units in its
inventory. Diphone units are usually obtained from recordings of a specific
speaker reading either "diphone-rich" sentences or "nonsense"
words. In both cases the speaker is asked to articulate clearly and use a rather
monotone voice. Diphone-based concatenative synthesis [7]has the advantage of
a moderate memory footprint, since one diphone unit is used for all possible
contexts. However, since speech databases recorded for the purpose of providing
diphones for synthesis do not sound "lively" and "natural"
from the outset, the resulting synthetic speech tends to sound monotonous.
For years, expert labelers were employed to examine waveform and spectrogram,
as well as their sophisticated listening skills, to produce annotations ("labels")
such as those shown in the bottom panel of the figure. Here we have word labels
(time markings for the end of words), tone labels (symbolic representations
of the "melody" of the utterance, here in the ToBI standard, [8] ),
syllable and stress labels, phone labels (see above), and break indices (that
distinguish between breaks between words, sub-phrases, and sentences, for example).
It turns out that expert labelers need about 100-250 seconds of work time to label one second of speech with the set depicted in Fig. 2 [9]. For a diphone-based synthesizer, this might be a reasonable investment, given that a "diphone-rich" database (a database that covers all possible diphones in a minimum amount of sentences) might be as short as 30 minutes. Clearly, manual labeling would be impractical for much larger databases (dozens of hours). For this, we would require fully automatic labeling, using Speech Recognition tools. Fortunately, these tools have become so good, that speech synthesized from an automatically labeled speech database is of higher quality than speech synthesized from the same database that has been labeled manually [10].
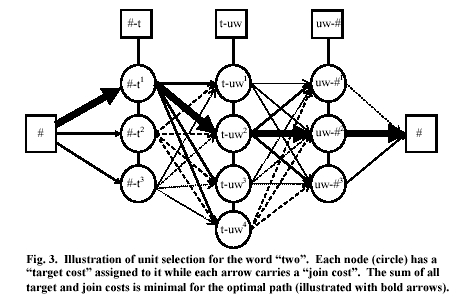
With the availability of good automatic speech labeling tools, Unit-Selection Synthesis has become viable for obtaining customer-quality TTS. Based on earlier work done at ATR in Japan [11][12][13], this new method employs speech databases recorded using a "natural" (lively) speaking style [14]. The database may be focused on narrow-domain applications (such as "travel reservations" or "telephone number synthesis"), or it may be used for general applications like email or news reading. In the latter case, unit-selection synthesis can require on the order of ten hours of recording of spoken general material to achieve high quality. In contrast with earlier concatenative synthesizers, unit-selection synthesis automatically picks the optimal synthesis units (on the fly) from an inventory that can contain thousands of examples of a specific diphone, and concatenates them to produce the synthetic speech. This process is outlined in Fig. 3, which shows how the method must dynamically find the best path through the unit-selection network corresponding to the sounds for the word 'two.' The optimal choice of units depends on factors such as spectral similarity at unit boundaries (components of the "join cost" between two units) and on matching prosodic targets set by the front-end (components of the "target cost" of each unit). In addition, there is the problem of having anywhere from just a few examples in each unit category to several hundreds of thousands of examples to chose from. Obviously, also, the unit selection algorithm must run in a fraction of real time on a standard processor.
In respect to quality, there are two good explanations why the method of unit-selection synthesis is capable of producing customer quality or even natural quality speech synthesis. First, on-line selection of speech segments allows for longer fragments of speech (whole words, potentially even whole sentences) to be used in the synthesis if they are found with desired properties in the inventory. This is the reason why unit-selection appears to be well suited for limited-domain applications such as synthesizing telephone numbers to be embedded within a fixed carrier sentence. Even for open-domain applications, such as email reading, however, advanced unit selection can reduce the number of unit-to-unit transitions per sentence synthesized and, consequently, increase the segmental quality of the synthetic output. Second, the use of multiple instantiations of a unit in the inventory, taken from different linguistic and prosodic contexts, reduces the need for prosody modifications that degrade naturalness [15][16].
Conclusions
The advent of high-quality text-to-speech (TTS) may have created the false notion
of speech synthesis being a "solved problem," that is, the idea that
speech synthesis can replace a live human speaker (or a speaker's recording)
in any application, service, or product. This is definitely not the case, given
the enormous richness and expressive capabilities of the human voice that is
impossible, or at least impractical, to match with a speech synthesizer. What
unit selection speech synthesis can do, however, is deliver surprisingly good
quality speech for somewhat narrow applications, such as, for example, travel
reservations, weather reports, etc. [17] The high quality is achieved by recording
special domain voice databases. For a given domain (e.g., "travel"),
voice talents are being recorded while reading examples from that domain, such
as "Your flight to <destination> has been confirmed." The idea
is to cover as much material as possible that is well suited for the given application.
Also, the reading style used (e.g., friendly but affirmative) has to be appropriate
for the application. What unit-selection TTS cannot do today (at least not in
any practical way) is to turn an average voice, reading in a "newsreader"
(i.e., reserved, toned-down) style, into a highly desirable "spokesperson"
voice for marketing a new product (i.e., speaking in a highly expressive, enthusiastic
style). The reason for this inability is simple: there is no way that all the
necessary speech data (many hundreds of hours) can be recorded from one single
speaker, given the time it would take and the fact that a speaker's voice might
change over time. We also do not know enough yet to use signal processing to
turn normal speech into highly expressive/emotional speech.
References
[1] Pickett, J. M., Schroeter, J., Bickley, C., Syrdal, A., and Kewley-Port,
D. (1998). Speech Technology, in: The Acoustics of Speech Communication, Ch.
17, J. M. Picket (Ed.), Allyn and Bacon, Boston, pp. 324-342.
[2] Sondhi, M. M., and Schroeter, J., Speech Production Models and Their Digital
Implementations, in: The Digital Signal Processing Handbook, V. K. Madisetti,
D. B. Williams (Eds.), CRC Press, Boca Raton, Florida, pp. 44-1 to 44-21, 1997.
[3] J. Allen, M. S. Hunnicutt, D. Klatt, R.C. Armstrong, D.B. Pisoni, "From
text to speech: The MITalk system," Cambridge Studies in Speech Science
and Communication, Cambridge University Press, 1987.
[4] R. Sproat, and J. Olive, "Text to Speech Synthesis," AT&T
Technical Journal, 74(2), 35-44, 1995.
[5] M. Ostendorf, I. Bulyko, "The Impact of Speech Recognition on Speech
Synthesis," Keynote Paper in: Proceedings IEEE 2002 Workshop on Speech
Synthesis, Santa Monica, Sept. 11-13, 2002.
[6] R. Sproat, J. Olive, "Text-to-Speech Synthesis," Ch. 46 in: The
Digital Signal Processing Handbook (V. K. Madisetti, D. B. Williams, eds.),
CRC Press, IEEE Press, 1998.
[7] D. O'Shaughnessy, L. Barbeau, D. Bernardi, and D. Archambault, "Diphone
Speech Synthesis," Speech Communication 7, pp. 55-65, 1988.
[8] Silverman, K., Beckman, M., Pierrehumbert, J., Ostendorf, M., Wightman,
C., Price, P., and Hirschberg, J., ToBI: A standard scheme for labeling prosody.
ICSLP 1992, pp. 867-879, Banff.
[9] Syrdal, A. K., Hirschberg, J., McGory, J. and Beckman, M., "Automatic
ToBI prediction and alignment to speed manual labeling of prosody," Speech
Communication (Special Issue: Speech annotation and corpus tools, vol. 33 (1-2),
Jan. 2001, pp. 135-151.
[10] Makashay, M. J., Wightman, C. W., Syrdal, A. K. and Conkie, A., "Perceptual
evaluation of automatic segmentation in text-to-speech synthesis," ISCLP
2000, vol. II, Beijing, China, 16-20 Oct. 2000, pp. 431-434.
[11] Y. Sagisaka, N. Kaiki, N. Iwahashi, and K. Mimura, K., "ATR - n-TALK
speech synthesis system," in: Proc. Int. Conf. on Speech and Language Processing
92, Banff, Canada, vol. 1, pp. 483-486, 1992.
[12] A. W. Black and P. A. Taylor, "CHATR: A Generic Speech Synthesis System,"
in COLING '94, pp. 983-986, 1994.
[13] A. Hunt, A. Black, "Unit selection in a concatenative speech synthesis
system using a large speech database," Proc. ICASSP, vol. 1, pp. 373-376,
1996.
[14] A. D. Conkie, "Robust Unit Selection System for Speech Synthesis,"
in: Joint Meeting of ASA, EAA, and DAGA, paper 1PSCB_10, Berlin, Germany, 15-19
Mar., 1999, available on-line at http://www.research.att.com/projects/tts/pubs.html.
[15] Beutnagel, M., Conkie, A., Schroeter, J., Stylianou, Y. and Syrdal, A.,
"The AT&T Next-Gen TTS System," Proc. Joint Meeting of ASA, EAA,
and DEGA, Berlin, Germany, March 1999, available on-line at http://www.research.att.com/projects/tts/pubs.html.
[16] M. Jilka, A. K. Syrdal, A. D. Conkie, and D. A. Kapilow, "Effects
on TTS quality of methods of realizing natural prosodic variations," Proc.
ICPhS, Barcelona, Spain, 2003
[17] A. Schweitzer, N. Braunschweiler, T. Klankert, B. Möbius, B. Säuberlich,
"Restricted Unlimited Domain Synthesis," in: Proc. Eurospeech 2003,
Geneva, 1321-1324, Sept. 1-4, 2003.