
Shiva Sundaram (shiva.sundaram@usc.edu)
and Shrikanth Narayanan (shri@sipi.usc.edu)
Speech Analysis and Interpretation Laboratory,
University of Southern California, Los Angeles,CA.USA
Popular version of paper 1aSC11
Presented Monday morning, November 15, 2004
148th ASA Meeting, San Diego, CA
1. Introduction 2. Laughter: Its Components and Synthesis
Speech is one of the basic forms of human communication. Verbal aspects of spoken
communication rely on words specified of to convey explicit intent and desires
in a communication exchange. However, speech also carries significant implicit
information such as intonation that exemplifies the context and the emotional
state of the speaker. Consider for example the sequence of words "did you go
to the post office." To use these words to pose a question, a speaker controls
his or her intonation. Of course this question can be relayed either plainly
or with any number of emotions such as a hint of harshness to express anger
or laughter to indicate something funny, or even sarcastic. As one can see even
in spoken communication, linguistic cues (as conveyed by words) are accompanied
by paralinguistic cues such as laughter to make up the rich communication fabric.
For a machine voice to sound truly natural, it is hence critical to be able
to capture the rich linguistic and paralinguistic details embedded in human
speech. Enabling automated synthesis of expressive speech is a critical area
in current speech communication research.
While the primary focus on past efforts in speech synthesis has been on improving
intelligibility, recent trends are targeting improving the emotional and expressive
quality of the synthetic speech. For instance, natural expressive speech quality
is essential for long exchanges of dialogues and for even information relaying
monologues. There are many components that play a role in imparting the expressive
emotional quality to speech. These include variations in speech intonation and
timing, the appropriate choice of words and the use of other non-verbal cues.
One of the key expressive quality types is happiness. It has been shown by prior
work by other researchers, and our own, that it is one of the most challenging
synthesis problems and that one has to look beyond intonation variation. Laughter
is one key attribute of this realm, and the focus of the present work.
This paper addresses the analysis and synthesis of the acoustics of laughter.
Our main application is to aid synthesis of ``happy-sounding" speech. In
most situations, happy speech may be better defined as speech that conveys positive
emotions. Subjective tests reveal that it is difficult to discern happy emotions
in speech purely on the basis of intonational differences. While in face-to-face
interactions it is possible to have happy speech without laughter, other non-verbal
cues such as facial expressions help the interlocutor to understand that the
underlying emotion is positive or happy. For speech-only situations, however,
laughter is often used as a cue to express happiness.
Different types of laughter are used by humans to express different levels of
gladness or elation. Furthermore, the same speaker may laugh differently in
different situations. The synthesis technique developed here assumes a dynamical
oscillator model for laughter. It has the provision to parametrically control
the laughter model and thus can be used to synthesize for a wide variety of
happy expressions. It can also be used to capture and generate speaker-specific
traits in laughter.
Laughter is a highly complex physiological process of breathing and voicing..
There is a wide variety of terminologies used to describe the various aspects
of laughter, hence a description relevant to this research follows:A short burst
or a train of laughter (i.e., a laughter bout), comprises two main components.
Voiced laughter-calls, utterances that excite the vocal chords and generate
sound, and unvoiced sounds, generated as breathing sounds with air passing through
the larynx without involving vocal chord vibrations. Usually, the voiced and
unvoiced parts alternate in a laughter event, but it is also possible that they
co-occur. Figure 1 shows a typical laughter bout illustrating these parts.
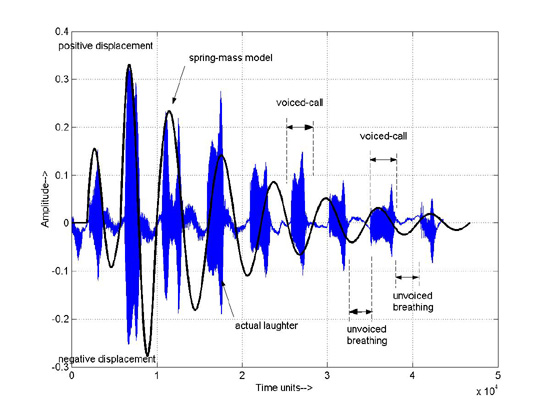
Figure 1
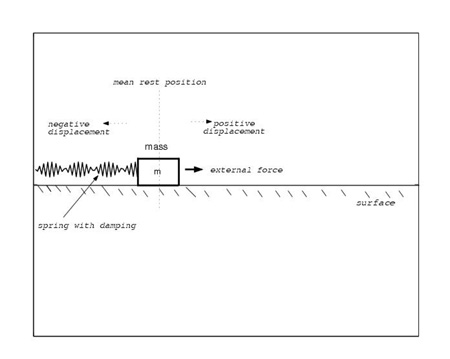
Figure 2
3.Conclusion and Future Work
It is important to point out that a comprehensive knowledge of effects of including
laughter in synthesized speech is necessary. For example, as presented earlier,
laughter can be used to express a wide variety of attitudes of the speaker,
it can be used to express both positive and negative emotional state. An in-depth
understanding can be brought forth from controlled subjective experiments for
which it must be possible to generate a variety of controlled laughter for the
sake of experimental repeatability. The synthesis technique proposed here can
be used for this purpose.
It is not always the case that there is a distinct segment in speech where laughter
is present to express gladness or a positive emotion. Often, speech and laughter
are articulated together (known as "speech-laughs''). The focus of our
ongoing research is to develop techniques to synthesize these so-called "speech-laughs.''