148th ASA Meeting, San Diego, CA
Study of Acoustic Correlates Associated with Emotional Speech
Study of Acoustic Correlates Associated with Emotional Speech
Serdar Yildirim - yildirim@usc.edu
Sungbok Lee, Murtaza Bulut, Chul Min Lee, Abe Kazemzadeh, Carlos Busso, Shrikanth
Narayanan
University of Southern California
Los Angeles, CA, 90089
Popular version of paper 1aSC10
Presented Monday morning, November 15, 2004
148th ASA Meeting, San Diego, CA
Human speech carries information about both the linguistic content as well
as the emotional/attitudinal state of the speaker. This study investigates the
acoustic characteristics of four different emotions expressed in speech. The
goal is to obtain detailed acoustic knowledge on how the speech signal is modulated
by changes from an emotionally neutral state to a specific emotionally aroused
state. Such knowledge is necessary for the automatic assessment of emotional
content and strength as well as for emotional speech synthesis which should
help develop a more efficient and user-friendly man-machine communication system.
For instance consider an automated call center application, where depending
on the detected emotional state of the user during the interaction -- such as
displeasure or anger due to errors in understanding user's requests -- the system
could transfer the troubled user to a human operator before premature man-machine
dialogue disruption. Similarly, development of speech synthesis systems capable
of emotional speech will enable the computer to interact with the user more
naturally such as by adopting an appropriate tone of the voice suitable to a
given situation.
In this study, emotional speech data obtained from two semi-professional actresses
are analyzed and compared. Each subject produced 211 sentences with four different
emotions: neutral, sad, angry, happy. We analyze changes in speech acoustic
parameters such as magnitude and variability of segmental (i.e., phonemic)
duration, fundamental frequency and first three formant frequencies as a function
of the emotion type. Segmental duration here means duration of spoken phoneme.
RMS energy is correlated with loudness of speech and the fundamental frequency
and formant frequencies are related to speaker's individual voice characteristics.
The changes of these acoustic or speech parameters over time are known to be
correlated with not only what is said but also how it is said. Therefore, change
in emotion is expected to be reflected in changes in such acoustic parameters,
when compared to those of neutral speech. Acoustic differences among the emotions
are also explored through mutual information computation, multidimensional scaling
and acoustic likelihood comparison with normal, neutral speech. Those are mathematical
methods which are used to quantify or visualize similarity among objects.
Current results indicate that speech associated with anger and happiness is
characterized by longer segmental durations, shorter inter-word silence, higher
pitch and energy with wider dynamic range. Sadness is distinguished from other
emotions by lower energy and longer inter-word silence. Interestingly, the difference
in formant pattern between [happiness/anger] and [neutral/sadness] are better
reflected in back vowels such as /a/(/father/) than in front vowels. Some detailed
results on segmental duration, fundamental frequency and formant frequencies,
and energy are given below.
Duration
Statistical data analysis (using analysis of variance, ANOVA) showed
that effect of emotions on duration parameters such as utterance
durations, inter-word silence/speech ratio, speaking rate, and average
vowel durations are significant. Moreover, our results showed that angry
and happy speech have longer average utterance and vowel durations
compare to that of neutral and sad. In terms of inter-word
silence/speech ratio, sad speech contains more pauses between words
compare to that of other emotions. Our analysis also indicated that sad,
angry, and happy have greater variability in speaking rate than that of
neutral speech.
Fundamental Frequency and Formant Frequencies
Our statistical analysis indicated that the effect of emotion on fundamental frequency
(F0) is significant (p < 0.001). The mean (standard deviation) of
F0 for neutral are 188 (49) Hz, for sad 195 (66) Hz, for angry 233
(84) Hz, and for happy 237 (83) Hz. Earlier studies report that
the mean F0 is lower in sad speech compared to that of neutral
speech [Murray93]. This tendency is not observed for this
particular subject. However, it is confirmed that angry and happy
speech have higher F0 values and greater variations compared to
that of neutral speech. As we can observe from Figure 1, mean vowel F0
values for neutral speech are less than that of other emotion
categories. It is also observed that anger/happy and sad/neutral
show similar F0 values on average, suggesting that F0 modulation
between the two within-group emotions.
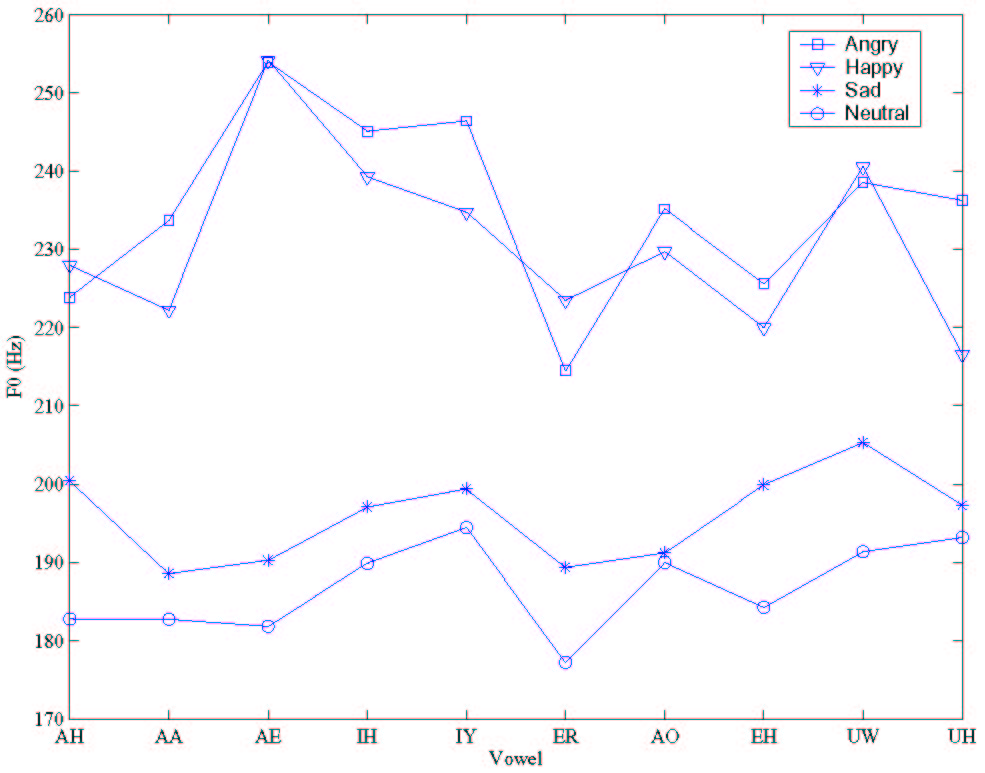
Figure 1: Average fundamental frequencies for vowels.
The first two formant frequencies for each emotion are shown in Figure 2a and in Figure 2b as a function of vowel identity. Two-factor ANOVA indicates that both the effect of emotion and the interaction between emotion and vowel identity are significant [F=115.3, p < 0.001 and F=37.4, p < 0.001 for the first formant and F=64.3, p < 0.001 and F=78.3, p < 0.001 for the second formant, respectively]. This suggests that the tongue positioning for a given vowel production can significantly vary depending on emotion to be expressed. Interestingly, difference in the formant patterns between the two groups of emotion (i.e., anger/happiness and sadness/neutral) are better reflected in back vowels such as /a/ than in the front vowels in this speaker. Difference in the manipulation of the lip opening and/or the tongue positioning at the rear part of the vocal tract could be underlying factors. It may be noted that we can't draw any conclusion on the variability of formant frequencies as a function of emotion as they vary depending on which formant is considered. For instance, the sad speech shows the smallest variability for F1, but it is the happy one for F2.
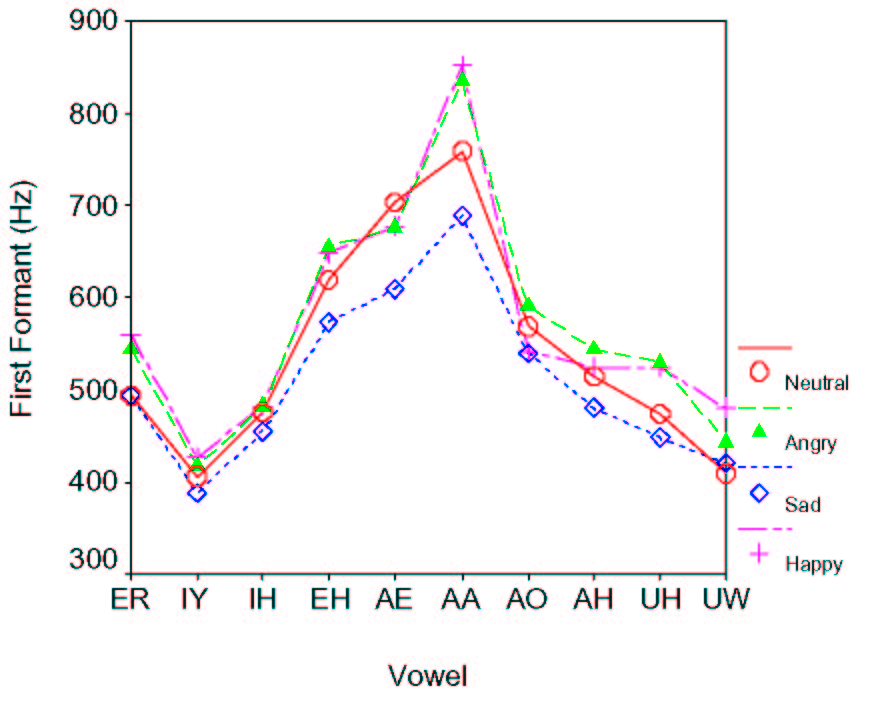
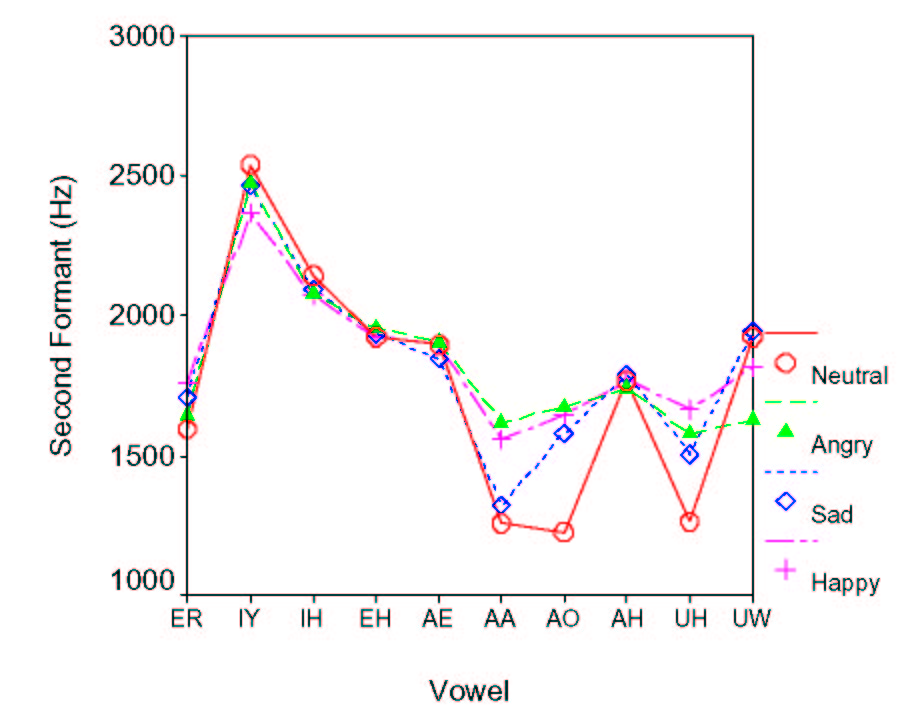
Figure 2: (a) Average first formant frequencies for vowels. (b) Average second formant frequencies for vowels.
Energy
Our analysis based on RMS energy showed that sad speech has less
median value and lower spread in energy than that of other emotions.
Angry and happy speech have higher median values and greater spread in energy.
Also, ANOVA indicates that effect of emotion is significant (p < 0.001).
According to our statistical analysis, RMS Energy is the best single
parameter to separate emotion classes.
Acoustic likelihoods associated with each emotional state are shown in Figure 3a. It is evident that anger and happiness share similar acoustic properties and the same tendency also holds for neutral and sadness. Two-factor ANOVA indicates that the effect of emotion on likelihood as well as the effect of phoneme class are significant [F=584.3, p < 0.001 and F=201.3, p < 0.001, respectively]. Furthermore, the interaction between emotion and phoneme class is significant [F=9.1, p < 0.001]. This suggests that the acoustic effects of emotional change are realized differently for different phonemes, probably depending on voiced or unvoiced distinction. A related observation is the larger separation of sad and neutral likelihoods for sonorants such as vowel and diphthongs. It seems that acoustic information associated an emotional change is conveyed more in sonornats than in obstruent sounds.
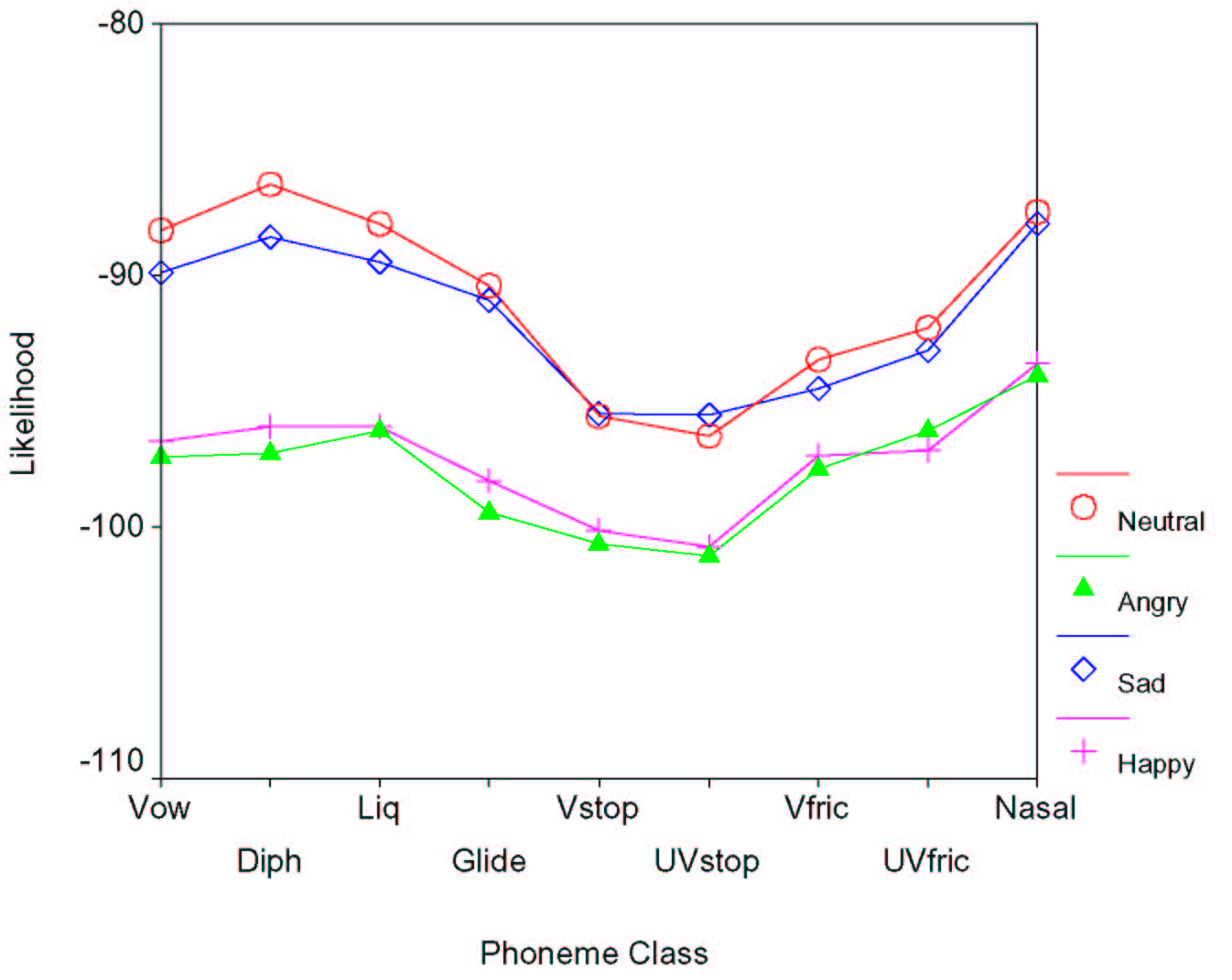
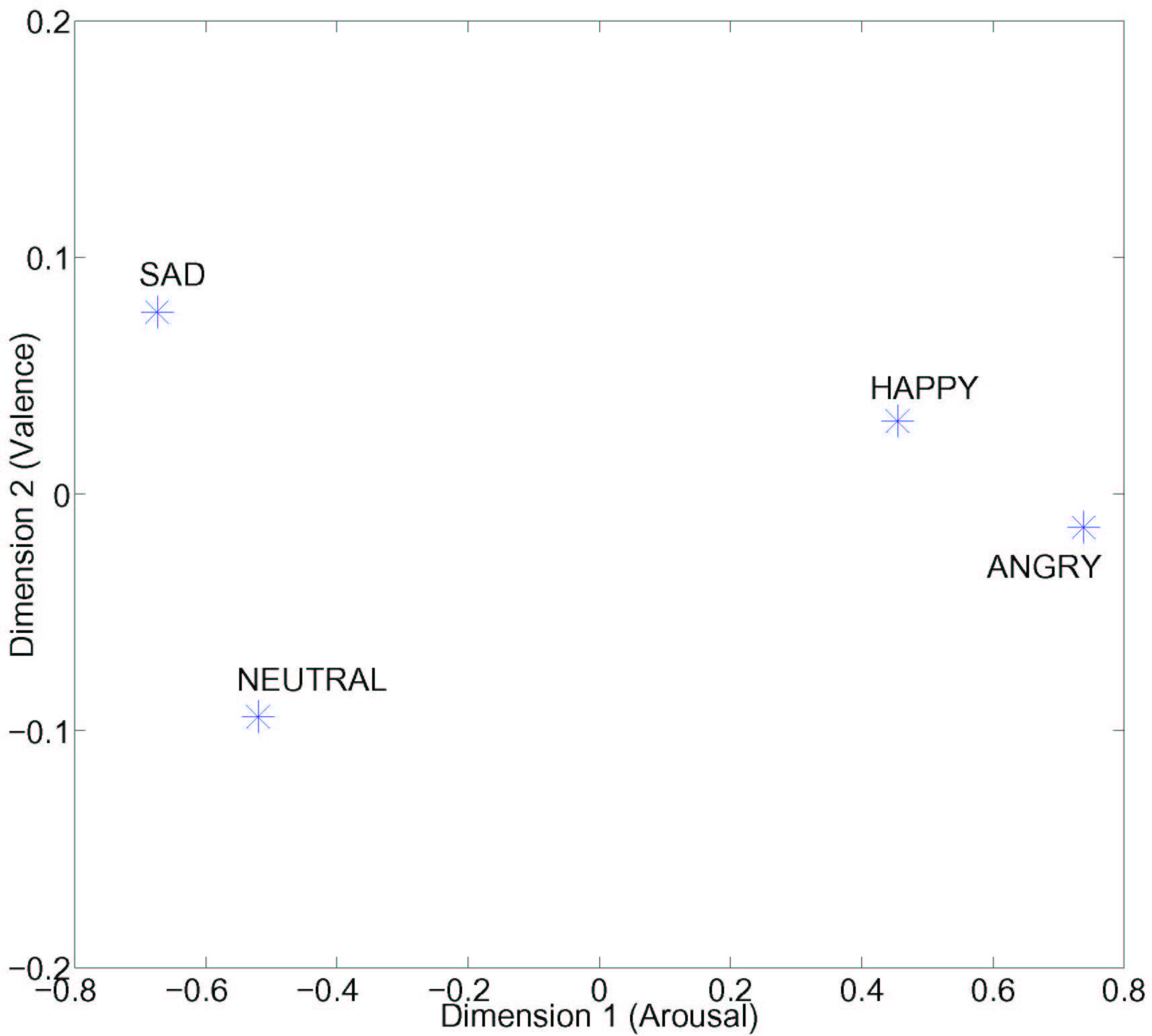
Figure 3: (a) Average Likelihood (b) Multidimensional scaling corresponding to F0 for emotion categories.
We also applied multidimensional scaling technique to visualize pattern of differences among emotional categories based on Kullback-Leibler distance between F0 distributions. As we can see in Figure 3b, similar patterns of F0 in terms of averaged value and distribution is evident between angry/happy and between sad/neutral. However, separation along dimension 2, possibly the valence dimension, is not very clear. Mutual information analysis
Pitch and RMS energy are two important prosodic cues to describing emotions. We used mutual information to find out the relation between pitch and RMS energy in a given emotion category. We estimate mutual information based on a joint probability estimation using 2-D histogram method. Higher value (in bits) implies more synchrony between F0 and RMS energy in speech production. It is clear from the Table 1 that there is more synchrony between F0 and RMS energy in speech production for angry and happy speech. More air flow through the vocal folds and more efforts producing angry and happy emotions may be the underlying reasons.
| emotion | Neutral | Sad | Angry | Happy |
| Mutual Info (bits) | 0.4810 | 0.5202 | 0.8189 | 0.7988 |
Conclusions
Emotions are one of those human qualities are extremely challenging to explain. Although there have been numerous studies with regards to both psychological and engineering aspect of emotions, it is still not clear how to define and how to categorize human emotions. For example, it is very difficult to find an universal definition for every emotion. Especially when we consider the fact the interpretation of the emotions can be unique for each individual because of his/her background, one should be very careful when generalizing the definitions of emotions. Even though the emotions studied in this study are among the so-called universal emotions, because they are perceived more or less similarly regardless of the personal background, still there are confounding similarities between emotions expressed in speech in terms of their acoustic characteristics. Only by analyzing acoustic cues of emotional speech from huge amount of emotional samples, and by comparative studies of these results, it will be possible to find a common denominator for describing emotions. Joint efforts across multi disciplinary fields such as engineering, psychology, sociology, linguistics and may others will eventually help us to understand emotions better. Isaac Asimov's "I, Robot" is no more as an impossible dream as it was years ago. Maybe not in the near future, but sometime "Robots" will start with an "I."
References
Murray, I.R., Arnott, J.L., "Toward to simulation of emotion in synthetic speech: A review of the literature on human vocal emotion.", JASA, vol. 93(2), pp. 1097-1108, 1993.