
Identifying Disguised Voices through
Speakers' Vocal Pitches and Formants
Jean Andruski*- j_andruski@wayne.edu
Nikki Brugnone + and Aaron Meyers*
*Department of Communication Sciences and Disorders, Wayne State University
+Department of Psychology, Wayne State University
Popular version of paper 4pSC9
Presented Thursday afternoon, June 7, 2007
153rd ASA Meeting, Salt Lake City, UT
The goal of this study was to compare the value of two kinds of features contained in the speech signal that may help listeners determine speaker identity when an individual is trying to disguise his or her voice. Research into speaker identification is concentrated in the private sector, as evidenced by the number of firms offering commercial voice-recognition solutions. Since much of this information is proprietary, there is a lack of published research on acoustic cues to speaker identity.
Established methods in forensics, or the use of speech as evidence in a court of law, focus on ear-witness testimony and acoustic features that are well-documented in published research. However, the published research tends to focus on features in the speech signal such as formants F1 and F2 (to be described in more detail later) that determine the identity of the sound (e.g., /t/ vs /d/ or /i/ vs. /e/). For this first set of cues, the difference between any two vowels produces a greater difference in the acoustic signal than two speakers saying the same vowel. Just as it is difficult to see the effect of a flashlight (speaker identity) added to that of a large searchlight (sound identity), the effects of speaker identity are hard to see in these cues. These acoustic cues, which do so much to identify the sound that is spoken, are strongly affected by articulation, the way an individual uses speech organs such as the lips and tongue to produce different sounds.
A second set of acoustic features in the speech signal, including the formants F3 and F4 (also to be described later) are substantially less affected by articulation. As a result, they provide little information on sound identity. Interestingly, phoneticians tacitly agree that, because these cues are not strongly affected by articulation, they probably provide information on speaker identity. There is, however, no published literature to support this conclusion. Is this the case? Are cues that make little contribution to the identity of speech sounds useful for determining speaker identity and are they more useful than cues that are strongly affected by articulation?
The speech signal has many acoustic features from which measurements can be taken. Starting as a vibration of the vocal cords, speech signals have a pitch or "fundamental frequency" (denoted F0) which is determined by the mass, length and tension of the speaker’s vocal cords. As the buzzing sound created by vocal fold vibration travels through the pharynx, oral and nasal cavities, it is modified by the length and shape of the air column through which it passes and becomes a speech sound. Articulation changes the sound that exits the mouth simply because it changes the shape and size of the air cavities used for speech.
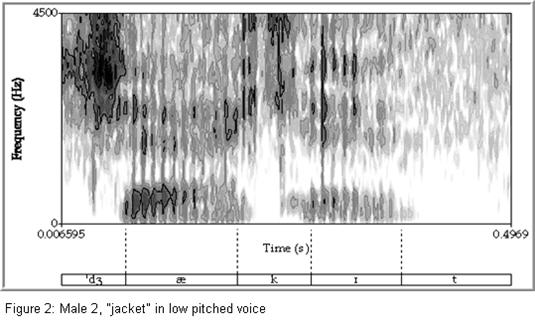
During the production of vowels, one of the most important features this creates is a series of vocal resonances called formants. A single formant is a bit like the sound you hear if you blow across the top of a bottle. Components of the noise made by your breath resonate in the bottle and are heard as a note. Similarly, components of the buzz produced by the vocal cords resonate in the air cavities of the vocal tract and are heard as a speech sound. Although the vocal tract produces an infinite number of formants, only the two lowest-frequency formants (designated F1 and F2) are usually required for listeners to hear all the different vowel sounds. Figure 1 provides an example of a word in which the formants of the vowel are marked. Formants are referred to by number, starting from the lowest frequency at the bottom of a spectrogram and moving up. For most voices, four to six formants can be seen in a spectrogram.
The frequencies of F1 and F2 are important cues to vowel identity. The difference between the vowel sounds in gate and goat, for example, is largely due to differences in F1 and F2. The formants above F1 and F2 provide relatively little information about speech sound identity. Since the next two formants (F3 and F4) can usually be seen and measured in spectrograms, they provide a practical starting point for comparison with F1 and F2. Vocal pitch (F0), which is also easy to measure, is another cue that provides very little information on speech sound identity. Presumably, pitch, F3 and F4 make little contribution to speech sound identity because they are not strongly affected by articulation (if you take away the searchlight, the effect of the flashlight can be seen.). Do they, then, provide information on speaker identity and are they more informative about speaker identity than F1 and F2?
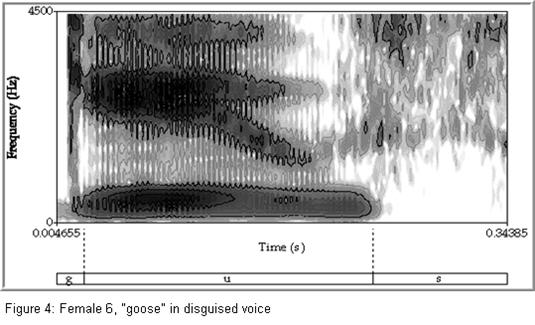
To better understand the relative value of these cues for speaker identification, this study analyzed recordings of five male and five female speakers. Participants read a prepared passage three times using their normal conversational voice, a pitch that was lower than they normally would use, and a vocal disguise of their choosing. For each recording, measurements of pitch and the first four formants were taken from 92 vowels using Praat (Boersma & Weenink 2007). Figures 1 and 2 provide examples of vowels produced by a male speaker in the normal and low-pitched voice conditions, and Figures 3 and 4 provide examples of vowels produced by a female speaker in the normal and disguised conditions. Data from the normal-voice condition was used to train a discriminant analysis. Discriminant analysis is a statistical tool that determines whether a set of variables provided by the user can be used to discriminate between two or more groups. In this case, the analysis used the normal pitch and formant measurements to develop a formula to discriminate between the different speakers. The effectiveness of this formula for discriminating between speakers was then tested by using it to classify data from the low-pitched and disguised voice conditions.

![]() Play the above sound
Play the above sound
![]() Play the above sound
Play the above sound

![]() Play the above sound
Play the above sound
![]() Play the above sound
Play the above sound
Several other interesting patterns relating to vocal pitch, and pitch and formant variability were seen in the data. All ten speakers raised the pitch of their voice and showed the greatest amount of pitch variation in the disguised voice condition. For eight out of ten speakers, pitch variability was lowest when they were speaking in their normal conversational voice. Earlier work (e.g. by Hecker et al. 1968 and Streeter et al. 1977) has shown that speakers tend to raise the pitch of their voice under stressful conditions, such as when they are lying. Attempting to disguise one's voice may produce a similar type of stress.
F1/F2 variability, which relates to variability in the way vowels sound, was lowest for all ten speakers in the low-voiced condition and highest for all ten speakers in the disguised-voice condition. The increased F1/F2 variability in the disguised voice condition suggests that speakers produce less stable vowel qualities when imitating another dialect or foreign accent than when using their own dialect. This may be because they have a limited understanding of vowel qualities in accented speech.
In the low-pitched voice condition, the frequencies of all four formants moved lower with the pitch of the voice. This is likely because the larynx drops to a lower position in the throat when speakers use a low-pitched voice, thus lengthening the entire vocal tract. Just as with families of musical instruments, larger cavities have lower resonant frequencies. Since this is a natural consequence of lowering the larynx, it implies that speakers cannot simultaneously lower pitch and raise formant frequencies when they try to disguise their voice. Patterns such as this suggest additional acoustic comparisons that may be effective for evaluating whether a given voice is, or is not, a known speaker using a vocal disguise.
References
ABRE Voice ID Board (1999). Voice comparison standards [pdf file] Downloaded from http://www.tapeexpert.com/pdf/abrevoiceid.pdf
Boersma, P. & Weenink, D. (2007). Praat: doing phonetics by computer (Version 4.5.16) [Computer program]. Downloaded from http://www.praat.org/
Hecker, M.H.L., Stevens, K.N., von Bismarck, G., & Williams, C.E. (1968). Manifestations of task-induced stress in the acoustic speech signal. Journal ofthe Acoustical Society of America, 44: 993-1001.