

[ Lay Language Paper Index | Press Room ]
Scott McDermott- sdm1718@cacs.louisiana.edu
Cheehung Henry Chu
Ctr. for Adv. Comput. Studies, The Univ. of Louisiana at Lafayette,
Lafayette, LA 70503
Popular version of paper 4aAA7
Presented Friday morning, November 30, 2007
154th ASA Meeting, New Orleans, LA
|
| Figure 1: Holodeck Rendering (Weinberger, 2007) |
|
| Figure 2: Immersive 3D Virtual Environment (Courchesne, 2007) |
Of the five human senses, vision is generally regarded as the most significant to survival. People constantly depend on sight in day-to-day life in order to navigate through their surroundings without accident or injury. Next in line of importance to survival would easily be the sense of sound. When one suddenly loses the ability to hear, he is almost as vulnerable as if he were blind. Audio cues constantly give volumes of information about what is happening in proximity to the listener. They allow individuals to avoid collisions with other objects, know where something or someone is relatively located, and especially facilitate communication. Keeping this in mind, in order to effectively create a virtual 3D environment, it must include sound and noise in any reproduction. Without accurate acoustics, a virtual 3D experience could easily be as frustrating as watching TV without the sound. Yet, is it enough to simply play the appropriate sounds for the environment? How accurately represented must the 3D sound be?
In order to answer this question, one must first understand the end result of what a 3D virtual environment, or virtual reality, is attempting to accomplish. To be concise, a user should find himself in a completely immersive experience in which it becomes difficult, if not impossible, to distinguish between reality and illusion. Ideally this would be similar to the "holodeck" portrayed in some science fiction shows (Figure 1), where the actors actually walk into a generated virtual environment and completely interact with the characters and the surroundings. However, the current level of technology in computer graphics, processor speed and bandwidth, haptic responses, and audio synchronization do not allow for this level of experience, so it must be approximated. Presently, some of the more advanced 3D environments use multiple screens surrounding the user, displaying in two-dimensions a computed 3D virtual environment (Figure 2). This gives a rough sense of visual 3D immersion. As graphical and general processing speeds increase, these will become even more convincing. However, most of these applications employ sound processing techniques and algorithms which are decades old or use none at all! It is uncertain why sound has taken a backburner to visual development (Flaherty, 1998), but there is evidence that sound processing is becoming more important to these immersive virtual environments. This is demonstrated by the fact that many programming libraries are being developed with at least some 3D sound algorithms.
This paper approaches the concepts and dilemmas associated with 3D virtual sound calculations. A brief description of the current consumer practices in 3D sound follows. Then the ideal solution to this problem is discussed. The full paper contains a simple, but thorough review of acoustics, physiology and psychology of sound perception, and the technical aspects of previous works and our solution to 3D sound.
 |
 |
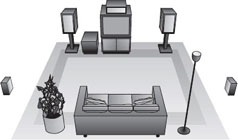
| Figure 3: Dolby 5.1 Speaker Placement (Hull, 1999) | Figure 4: The Neumann KU 100 Dummy Head (Neumann, 2007) |
Surround sound is described as a specific placement of speakers around a listener to achieve the illusion of sound coming from any or all directions (Hull, 1999). It also typically describes the method of dispersing the sound signal to these speakers and any filter effects placed on the original source to achieve the desired 3D spatialization results. Some examples of surround sound include a "wide stereo" effect on two speakers or headphones, DTS (Digital Theater Systems), THX, or most commonly Dolby 5.1, as well as 6.1 and 7.1, (Figure 3) which is typically included in the average home stereo system. In this paper, we do not propose to replace or modify this or any of these systems, as they are ubiquitous and standardized, but rather, we wish to send better, more accurate information to the surround sound speakers via the Application Programming Interface (API) layer of the computer system. The computers sound API will still need to know the speaker placement configuration. However, our algorithm will always generate the same output for a given virtual situation regardless of the speaker setup, and the sound API is allowed to express the results through the speaker system as it sees fit.
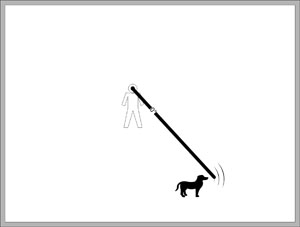 |
| Figure 5: Adding First-Degree Reflections |
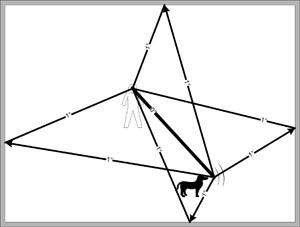 |
| Figure 6: Zero-Degree Reflections |
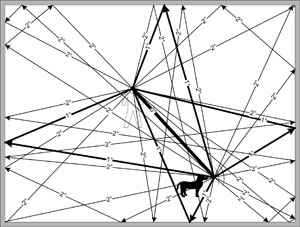 |
| Figure 7: Up to Second-Degree Reflections |
An intuitive approach to designing sound synthesis systems is to consider how one would perceive the sound given a particular environment. The Head Related Transfer Function (HRTF), relates the signal one would receive through his aural system to the assorted external acoustic factors. In practice, it is little more than an organically designed set of filters performed on a sound to make it seem to come from a specific direction (Burgress, 1992). The filters are typically carefully designed and based on good acoustic and physiological assumptions. Yet, they are limited in many ways.
The concept of HRTF is rather simple. An accurate model (Figure 4) of a typical ear, head, and sometimes even upper body is used to listen to a variety of sounds from a range of locations and orientations around the avatar. The model can even be a living person. Deep in the ear, near the eardrums, microphones are placed to capture the signals, representing how the human ear receives sounds. These signals are analyzed to reverse-engineer a series of filters that can be applied to sounds in order to replicate perceived spatialization.
Though the results are efficient and even somewhat convincing, HRTF implementations have several well-known inadequacies. First of all, the generated filters are only accurately matched to the model used. Since every human is anatomically different, this approach inherently cannot be generalized. Furthermore, the generated filters are expensive to create and are typically tightly tuned to a specific environment for which they were created, such as an auditorium or a padded room. Though some assumptions can be made to generalize the surroundings, HRTF is fundamentally only effective in the specific recording circumstances.
The current standards of producing 3D audio are at least marginally convincing. It is not unusual to see a head turn when a listener is immersed in a video game or a movie. However, we, as a society, have grown accustomed over the last few decades to accept what has been handed to us by the industry, mostly due to lack of innovations and better alternatives. We go to movie theaters and play sophisticated video games and marvel at the fidelity of the virtual environment. Yet we still allow ourselves to be lulled by acoustic technology that is fundamentally decades old. This occurs despite the fact that processor speeds continue to dramatically increase, thus negating the complexity of computation argument. It is past time to begin designing true 3D acoustic algorithms for use in our everyday lives.
The goal of this project is to efficiently generate the impulse response (described in the full paper) between the sound source and the listener for any set of locations in the entire room or environment. This response will be an array of echo volume losses which can be used to play back the sound. Sound will travel numerous paths, reflecting off of walls and other objects, and finally reaching the listener at various times and strengths. For each of these paths, or impulses, the computer will in effect replay the original sound while applying appropriate filters.
The overriding question is how to calculate an impulse response efficiently and accurately. Inherent difficulties include the depth, or order, of reflections to compute (i.e. how many bounces off of the walls will each path take, see Figure 5, Figure 6, and Figure 7), allowing for dynamic listener and sound source locations and orientations, multiple-roomed structures, changes in the virtual environment, object interference, material absorption and dispersion, refraction, and latency. All of these challenges will be addressed in the full paper, but it is worthwhile now to delve into latency and its impact.
Latency, or the amount of delay incurred due to the computations, is the primary determining evaluation of an algorithm. Presently, applications which are not designed to run in real-time can analyze spaces such as concert halls and sound rooms for acoustic anomalies. The algorithms used in these programs are considered comprehensive, but they are far too slow for real-time applications such as virtual environments. The human ear can actually tolerate up to a 150 ms delay (Wu, Duh, Ouhyoung, & Wu, 1997) from the initiation of a sound to the actual time it is first heard. Thus, any valid algorithm must have a maximum latency below this threshold. As is demonstrated in the full paper, it is impractical to generate an impulse response using standard techniques in real-time without significant optimizations.
Our initial approaches take simple, direct routes to 3D calculations. Fundamentally, we treat sound as it is meant to be treatedas a spherical wave increasing in diameter from the source. We consider sound to radiate out in all directions from the sound source and use this to calculate the various orders of reflection. Assuming that we have the geometry of the scene readily available, these computations generally break down to simple trigonometry. Even when traversing through different rooms, the math, if properly considered, is not entirely complicated. We also allow for the flexibility to compute only the depth of reflections that the processor can handle which eventually will be dynamically set, presumably to account for speed and processor load. Furthermore, the breadth can be set to limit computation complexity by setting the number of directions, granularity, stereo vs. mono, cut-off level, or any aspect specific to the desired algorithm.
Currently, the simulator (Figure 8) includes limited executions of the first two algorithms. Future development should include other algorithms such as the physics and stochastic models. All of these algorithms are described and analyzed in the full paper.
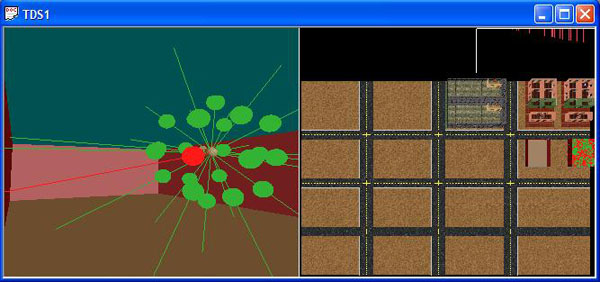 |
| Figure 8: TDS Running the Bouncing Reflections Algorithm |