



Automatic Detection and Correction of Detuned Singing
Popular version of paper 001462 (2aSCa4)
Presented Tuesday morning, July 1, 2008
Acoustics '08 Paris, Paris, France
Introduction
Comparing a studio recording with its concert version one can often notice that the first version is much better with the regard to the artist’s playing or singing in tune. One reason for this is the obvious possibility of performing many takes while recording in studio which makes it possible to achieve results meeting the artist’s taste and the producer’s expectations. The number of such takes is however limited by time and money spent on production, and slightly out of tune excerpts are often not noticed until mixing stage when the recording session is already closed. In such cases, thanks to the rapid development of a modern technology, mistakes can be corrected using the so-called “pitch shifters”.
In this paper the system engineered for automatic detection and correction of detuned singing, based on best possible combination of commonly used voice analyzing and processing methods, is presented. Also, improvement based on automatic variable frame length selection is proposed.
Construction of a typical pitch correction system
A typical pitch correction system consists of three main blocks (fig. 1).
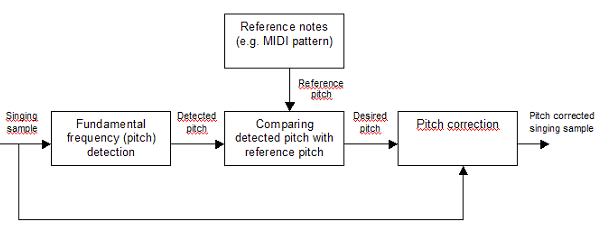
Fig. 1: Basic structure of a typical pitch correction system
The first one is responsible for retrieving a pitch of each note from a sung or played melody contained in an audio file, such as for example .wav format. Each musical note contains fundamental frequency and harmonic frequencies being its multiplication. The block task is to properly detect all these frequencies among frames of partitioned singing sample signal. There are two common types of methods used to detect fundamental frequencies, i.e. the so-called time-domain methods and frequency-domain methods. Using the first type one can retrieve fundamental frequency directly from the time form of a signal (e.g. the form of a signal directly contained in a wave file), without the need of complex transformations.
The frequency methods of fundamental frequency detection are based on the analysis of a signal spectrum, which is the representation of the volume of sound components depending on the frequency of these components. Such an analysis is obtained on the basis of the Fourier transformation of a time form of a signal into frequency domain. Analyzing a distribution of peaks composing spectrum it is possible to define fundamental frequency (pitch) of a sound, and its harmonics.
The task of the second block in the structure of a typical pitch correction system is to compare pitches retrieved from the singing sample with the reference notes, usually contained in a MIDI pattern or determined by the composition key entered by a user. Basing on the results of such a comparison it is possible to determine in which way notes should be corrected. Correction is the role of the third block of the system. Similarly to the fundamental frequency detection, pitch correction can be performed in time domain or frequency domain. The pitch shifting in the first type of methods is basically stretching or squeezing the fundamental period within each frame of the partitioned signal. In the frequency-domain methods correction bases on shifting peaks of a spectrum with retaining existing relationship among them.
Developing own pitch correction system
Defining bases for a pitch correction system based on methods mentioned above it is important to specify what kind of signal is going to be corrected and what type of correction is desirable. Such specification is especially important for choosing appropriate pitch correction method as each method has its typical advantages and drawbacks determining the environment in which it can be used with success. For example, using frequency-domain methods it is possible to correct pitch in polyphonic signals while time-domain methods enable to process only monophonic signals. Moreover, with frequency-domain methods one is able to drastically increase or decrease pitch (e.g. by two octaves) while doing the same using time-domain methods may result in chopped and unacceptable signal. However, most basic frequency-domain methods may introduce unwanted audible changes to the sound. The larger shift, the more audible negative effect.
To confirm above mentioned statement objective measurements of two fundamental frequency algorithms, i.e. fast autocorrelation (time-domain method) and HPS (Harmonic Product Spectrum; frequency-domain method), and two pitch correction algorithms, i.e. PSOLA (Pitch-Synchronous Overlap-Add; time-domain method) and modified phase vocoder (frequency-domain method) were performed together with listening tests. The algorithms’ codes came from Connexions website. The algorithms were examined in all four possible combinations. Research was based on male and female glissando singing samples. Obtained corrected signals for male glissando articulation, according to the algorithm combinations, are presented below. The correction employs increasing the first tone of the glissando by a whole tone and a half and preserving it for the whole duration of the sample.
LISTEN: Fast autocorrelation with PSOLA algorithm
LISTEN: Fast autocorrelation with modified phase vocoder
Basing on the comparison of the results it was stated that the combination giving best results is HPS algorithm and PSOLA. It was assumed that the aim of the designed system was to correct detuned monophonic singing signal and there was no necessity for large pitch shifts. Therefore, PSOLA algorithm was the right choice in that case, because the resulting signal was of a better quality than the one obtained using modified phase vocoder.
Analyzing results obtained using the implemented system it was concluded that a very important factor for quality of correction is the frame length mentioned earlier. Before proceeding with the fundamental frequency detection or pitch correction, a signal must be partitioned into smaller overlapping parts, called frames. The task of the fundamental frequency detection is to detect pitch in each single frame. If the frame is of a such length that the short fragment of melody which corresponds to it contains more than just one note, then the algorithm as a resulting pitch indicates one of the pitches of these notes. Therefore, one could consider very short frames to be the right solution. However, the shorter frame the poorer quality of a corrected signal. Below, there are two audio samples corrected using different frame lengths to present this phenomenon.
As a solution an additional frame length selection module was engineered in the system, which bases on the note duration retrieved from the MIDI pattern. In such a method frame lengths can vary and they depend on duration of a note, song tempo and a distance from neighboring notes within time sequence.
The system was implemented in JAVA programming environment as it provides many free libraries for work with sound. In fig. 2 a main window of the application engineered is presented.
Fig. 2: The main window of the detuned singing automatic detection and correction application
Conclusions
In the paper a basic structure of a typical pitch correction system along with commonly used methods and algorithms was presented. The algorithms were reviewed in the context of their drawbacks, essential while dealing with human singing correction. There were four possible combinations of chosen algorithms examined and basing on the best results obtained for human voice our own system of detuned singing correction was developed. It was stated that the weak point and a feature determining the quality of correction was the optimum choice of the frame length. Therefore, further improvements of the system should consist in variable frame length selection module basing on time values of notes contained in the MIDI pattern. Using methods described in the paper along with the improvements proposed a simple system of relatively good quality in comparison with much more complex systems was developed.