



Speak to your TV, it can understand you.
Maurizio Omologo
Fondazione Bruno Kessler - IRST
Via Sommarive, 18, Povo
38050 Trento, Italy
omologo@fbk.eu
Popular version of paper 2aSCc4
"Front-end processing of a distant-talking speech interface for control of an interactive TV system"
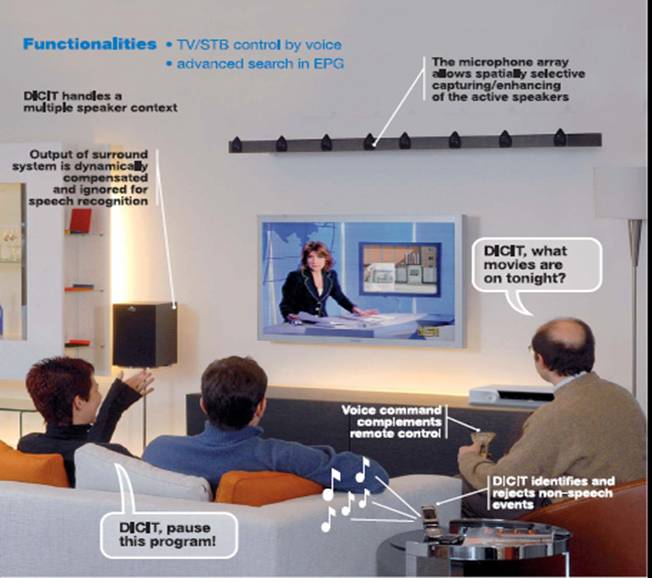
Sitting comfortably on your sofa, far away from your TV and from your Set-Top-Box, you can control your devices by voice. In fact, based on some microphones placed near the TV, a smart system analyzes the so-called “acoustic scene”, it verifies your identity, understands where you are and what you are saying, and eventually executes the given command.
The above-mentioned scenario inspires the research and development activities being conducted under DICIT (Distant-talking interfaces for Control of Interactive TV), a European Project of the Sixth Programme Framework, coordinated by Fondazione Bruno Kessler (Trento, Italy) and including the following partners: Alpikom S.p.A. (I), Amuser S.p.A. (I), Elektrobit Automotive GmbH (D), Fracarro Radioindustrie S.p.A. (I), Friederich-Alexander University (D), IBM Ceska Republica (CZ).
Disappearing computers, ubiquitous systems, invisible interfaces represent the way we expect human beings to interact in the future with most automated systems. State-of-the-art research on acoustics scene analysis and distant-talking speech recognition is already focusing on some of the more difficult problems towards this direction. Voice-enabled remote control of a TV represents just one of the many examples of smart-home application for these technologies.
The main objective of the DICIT project is the integration of distant-talking speech recognition as a complementary modality to the use of remote control in interactive TV systems. Augmenting the remote control device with speech may provide a suitable means to greatly ease information navigation and search. In the given scenario the system will recognize commands spoken by multiple users, even in the presence of interferences and background noise typical of the home environment. The final prototype will be able to handle English, German, and Italian languages, for accessing a Set-Top-Box system and the related services.
Although some voice-enabled remote control devices are available in the market, their use is limited by several constraints, most notably the distance between the user and the microphone: the user needs to know that the microphone must be used in a specific way, that the TV can not be too loud or too close to it, and that the environmental noise may represent a serious problem. Under DICIT, the main challenge is to investigate solutions that show the potential of an invisible acoustic sensing: users will not have to control anymore their position with respect to that of the microphone, they will not need to hold a microphone in their hand under severe noisy conditions or in the presence of other talkers.
To this purpose, several scientific and technical challenges are being tackled. For instance, one needs to produce a technology able to detect only the user voice, even when the loudspeakers are close to the microphones and are reproducing the TV audio loudly. Moreover, the system has to be smart enough to focus only on the user and neglect any other interfering sound source as, for instance, a cellular phone that is ringing, or a kid who is crying in the neighborhood.
This goal can be pursued by addressing and solving some basic technical problems. This paper deals primarily with two of them, namely, multi-speaker location and distant-talking speaker identification:
More details about the achievements so far obtained under DICIT can be found in the related web site http://dicit.fbk.eu. Some videoclips showing the capabilities of the first prototypes can be downloaded both from the above-mentioned web site and from http://www.fbk.eu/.
The interactive TV scenario addressed under DICIT. © DICIT consortium, Photo by Bernardinatti