Why is Speech So Difficult to Understand
for Persons with Hearing Loss? Using Models of Auditory Processing to Predict
Speech Performance in Noise
Ken W. Grant - kenneth.w.grant@us.army.mil
Van Summers - walter.summers@us.army.mil
Joshua G.W. Bernstein - joshua.g.bernstein@us.army.mil
Sandeep A. Phatak - sandeep.phatak@us.army.mil
Matthew J. Makashay - matthew.makashay@us.army.mil
Elena Grassi - elena.grassi@us.army.mil
Golbarg Mehraei - gmehraei@gmail.com
Walter Reed Army Medical Center
Army Audiology and Speech Center
6900 Georgia Ave., N.W.
Washington,
DC 20307-5001
Popular version of paper 2pPP6
Presented Tuesday afternoon,
April 20, 2010
159th ASA Meeting, Baltimore, MD
A
common complaint of persons with impaired hearing is that they can hear a
person talking, but they have difficulty understanding what the person is
saying. Even when the talker raises his
or her voice, the speech message remains distorted. Some patients liken this to listening to a
radio that is slightly mistuned. Turning
up the volume control on the radio does not make the sound clear. This example illustrates the distinction
between the two components of a hearing impairment: reduced audibility (poorer
thresholds to hear or detect the sound), and suprathreshold distortion
(distortions or reductions in signal quality that exist even when the sound is
made comfortably loud). Unfortunately, these suprathreshold distortions seem to
manifest themselves especially in noisy listening situations - the very
situations in which persons with impaired hearing typically report the most
difficulty listening.
Modern-day
hearing aids function mainly to amplify sound; that is, to make sound
louder. They typically do little to make
comfortably loud sounds clearer. The suprathreshold distortion introduced by
hearing impairment is little affected by the improved threshold sensitivity
provided by amplification. To address
this second component of hearing impairment (suprathreshold distortion), a
different kind of signal process from simple amplification must be provided.
The
focus of our research efforts at Walter Reed for the past several years has
been to characterize the degree and type of suprathreshold distortion in
individual hearing-impaired listeners. Standard clinical
assessments of hearing capacity do not predict reliably a patients speech
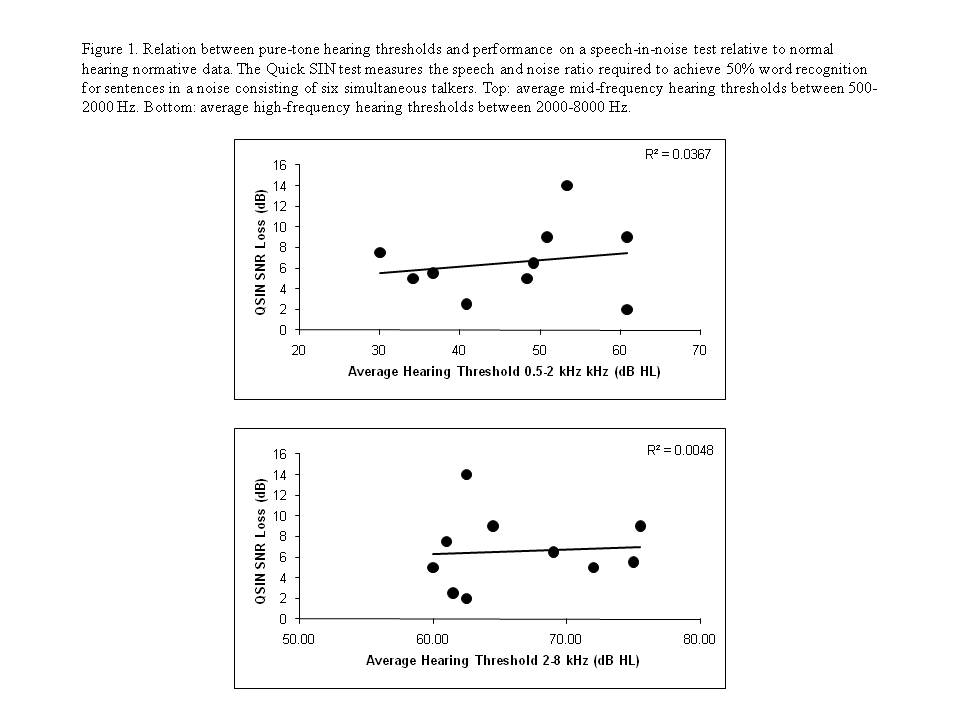
recognition performance under noisy conditions. Figure 1 illustrates
these points for a group of ten hearing-impaired patients.
The graphs in Figure 1 show the average
hearing threshold at 500, 1000, and 2000 Hz (top) and the average hearing
threshold at 2000-8000 Hz (bottom) versus scores on a clinical speech-in-noise
test know as the Quick SIN. The Quick SIN measures the speech-to-noise (SNR)
ratio required to receive 50% words correct on a sentence test compared to data
obtained from normal hearing persons. The resulting score is a SNR difference
between the hearing-impaired score and the normal hearing score, or SNR loss. As
can be readily seen, there is little relation between the average hearing loss
and a listeners ability to recognize speech in noise. In order to better understand the variability across hearing-impaired
listeners to understand speech in noise we have begun to develop models or
simulations, of auditory signals processed through hearing-impaired ears. The
models use mathematical formulations of auditory processing to transform sound
into dynamic time-frequency fluctuations thought to be important to the brain
when decoding and classifying speech sounds into meaningful language units. Model
parameters are adjusted using data obtained in separate experiments on
individual patients to reflect elevated
auditory thresholds, as well as suprathreshold distortions related to loudness
recruitment and reduced spectral resolution. Loudness recruitment refers to an abnormally
rapid growth of perceived loudness as the input signal is increased in level.
Hearing-impaired individuals are thought to have a more rapid growth of
loudness than normal hearing individuals. We assess this aspect of auditory
distortion by a measure of cochlear compression, or the amount of output gain
at different frequencies as a function of input level. This measure tells us
how much gain the cochlear provides to weak, medium, and high-level input
signals. Spectral resolution refers to how well
listeners can process different sounds presented simultaneously to different
frequency regions. For example, if you are played a low tone near middle C
(approximately 256 Hz) at a loud but not uncomfortable level, are you able to
detect a very weak higher tone about a half-octave up around 362 Hz? If you
have normal hearing, the level of the 362 Hz tone required to just be
detectable would be about the same regardless of whether the tone at middle C was
there or not. However, for many hearing-impaired listeners, the presence of the
tone at middle C will have an impact on the ability to hear the 362 Hz tone,
and the higher tone will have to be made louder than if it were played alone in
order for it to be detected. In auditory modeling, the early stages of
processing are often thought of as a number of separate channels or filters
much like the keys along a piano. The shape and sharpness of the filters
determines the number of distinct keys from low to high frequency. We can
estimate the shape of these channels by asking normal hearing and
hearing-impaired patients to detect tones of different frequencies in the
presence of narrow bands of noise positioned both lower and higher in frequency
than the target tone. By measuring the interference of these noise bands on tones
at different frequencies and at different levels, its possible to estimate the
shape of the filter at the tone frequency and how this shape changes with
level. For each listener tested, we constructed a
separate auditory model incorporating threshold, filter shape, and amplitude
compression. We also constructed a model representing normal hearing with data obtained
from a group of normal hearing individuals. By playing speech signals and noise
to the different hearing-impaired models and comparing the model outputs to that
of the normal auditory model, we are able to quantify differences between what
speech might look like to the normal ear/brain versus the impaired ear/brain.
These differences are then converted into a score that can be used to predict
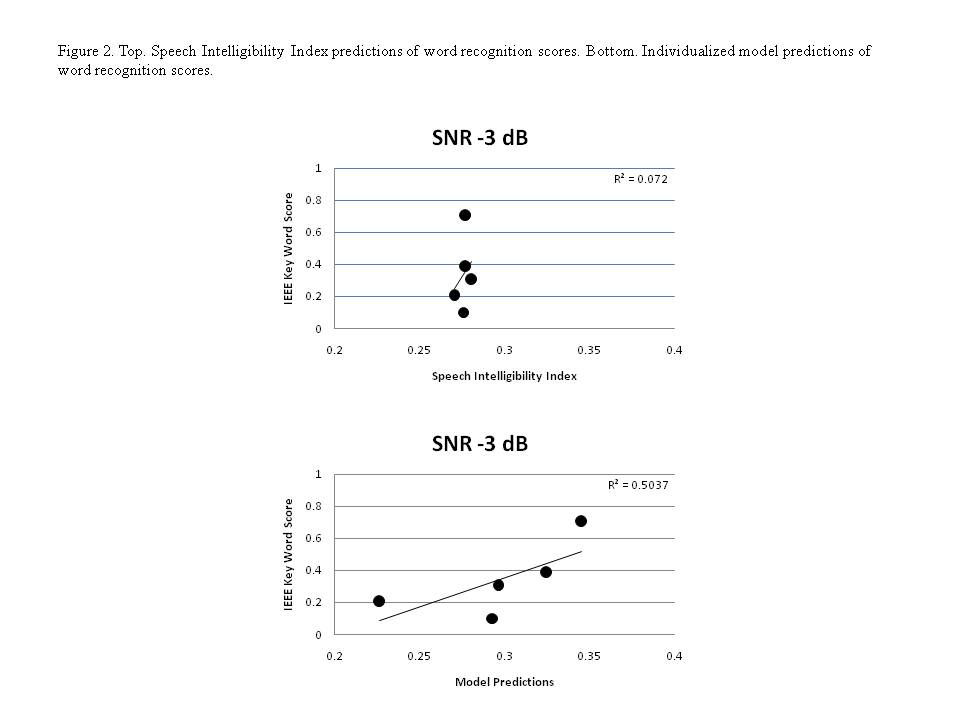
speech recognition, and the predicted scores are compared to actual scores. Figure 2 shows the modeling results for five
patients listening to speech in noise at a SNR of -3 dB. The top panel shows
results as a function of a simple model of audibility alone (Speech
Transmission Index). The bottom panel shows the results of including
suprathreshold distortion factors as well as audibility. Each model score is a
comparison between speech and noise passed through a simulation of the
individuals distorted auditory system and speech alone passed through a
simulation of a normal ear. The figure shows that we can account for the differences
across hearing-impaired listeners to a much greater extent than when only
threshold data are considered. This work highlights the need to incorporate
factors related to suprathreshold distortion in order to predict more
accurately speech understanding in noise. From a practical point of view, these
models, if proven to be robust across a larger number of hearing impaired, can
serve as a tool for predicting performance and for developing new signal
processing strategies for advanced hearing aids that attempt to compensate for
suprathreshold distortions. Conceptually, this is similar to what hearing aids
do now by amplifying different frequencies depending on the degree of hearing
loss and by applying amplitude compression to compensate for reduced dynamic
range. Because the types of suprathreshold distortion are very complicated and
can change dynamically with input level, the kinds of signal processing
anticipated are likely to be quite complex. Our efforts to characterize the
suprathreshold distortion in individual listeners and to embed them into a
model of auditory processing that includes peripheral (cochlear) and central
(auditory cortex) representations have demonstrated feasibility of this
concept. Future work to include additional measures of hearing capacity, such
as pitch perception, will likely improve our efforts to model the
suprathreshold distortions introduced by impaired hearing.