Alexis K. Black – akblack2g@gmail.com
Linguistics, University of British Columbia
Totem Field Studios
2613 West Mall
Vancouver, British Columbia, Canada V6T 1Z4
Popular version of paper 5aSC3
Presented Friday morning, May 27, 2011
161st Meeting of the Acoustical Society of America, Seattle, Washington
Have you ever yawned immediately after your neighbour yawned? Or accidentally adopted your friend’s accent for a word or two? Or maybe you pronounced a word (like “tomato”) the way your boss just said it, even though you usually say it the other way? People imitate one another in ways like this, and in even more subtle ways, all the time.
Sometimes we are conscious of these behaviours. Studies have also shown, however, that mimicry is frequently unconscious. For example, people have been shown to unconsciously imitate foot-tapping, face-touching, or head-scratching. We unknowingly mimic facial expressions, and sometimes even imitate the emotion associated with that expression. And we unconsciously imitate acoustic features of speech at all ages, and in diverse social situations. Despite its frequency, however, there is still much about this phenomenon that we do not understand.
For example, are certain people more likely to imitate than others? Are certain people more likely to be imitated than others? Are all acoustic features equally imitable?
This study examined these questions. We asked whether there are differences between men and women in degree or type of imitation, and whether people with higher or lower emotional reactivity might be more likely to imitate. We also asked whether imitation of vowels is different from imitation of consonants. Our results indicate that all of these factors – gender, emotional reactivity, and the type of sound -- influence imitation.
In the experiment, participants were first asked to read a list of words from a computer screen. They then went through an exposure phase where they heard two model talkers (a male and female) speaking a nearly identical list of words in random order. In the final phase, participants were again asked to read the words as they appeared on the computer screen. The amount that a person imitated the male or the female model was then calculated by comparing the participant’s baseline pronunciation with their post-exposure pronunciation. This process yielded a pre-exposure production of target words and a post-exposure production, from which we were then able to calculate the degree to which a participant changed their production as a result of exposure to the model talker; this is what we interpret as imitation.
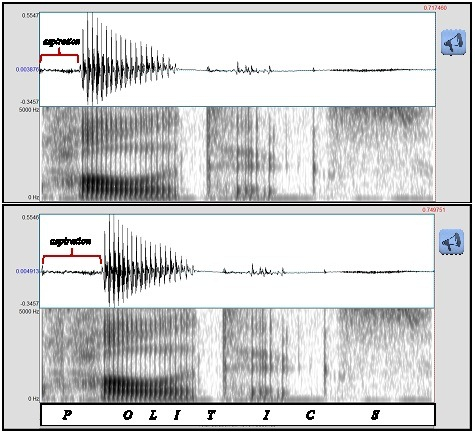
Participants were assigned to one of two conditions. As mentioned above, in both conditions participants were exposed to the speech of both a male and female model talker. However, in the first condition (the Female-Modified Condition), the female voice had been systematically modified. In the Male-Modified Condition, on the other hand, the male voice had been modified. The acoustic modification was identical for both model talkers, and involved only those stimulus words that began with a “p.” For these words, the aspiration (i.e. the burst of air that follows a “p” at the beginning of words) was extended by 40 msec. This alteration allowed us to track whether the participants’ speech gravitated more to either the male or female voice.
Figure 1. These two panels are visual representations of the male model talker’s production of the word “politics.” The top panel is the original, unmodified version of the word. The bottom panel illustrates the same word, but this version has been artificially modified so that the “p” is 40 msec longer than the original. Click the loudspeakers to the right of each panel to hear the difference.
Perhaps the most interesting finding was that, for the modified acoustic feature (aspiration), men imitated women, and women imitated men. People’s imitation of vowel qualities showed a similar trend for women; men were less likely overall to imitate vowel quality. This cross-gender pattern is not predicted by current linguistic theories. It may, however, answer a question that has been raised by previous imitation studies. These studies alternately found that men imitate more than women, women imitate more than men, or that they imitate to equal degrees. Our results demonstrate that the model’s gender as well as the participant’s is important for imitation.
We also discovered that different people imitate different acoustic features. People with low emotional reactivity were more likely to imitate vowels, whereas people with higher emotional reactivity were more likely to imitate consonant aspiration. The meaning of these results is less clear; future research will explore how acoustic features might signify different kinds of social and emotive associations.
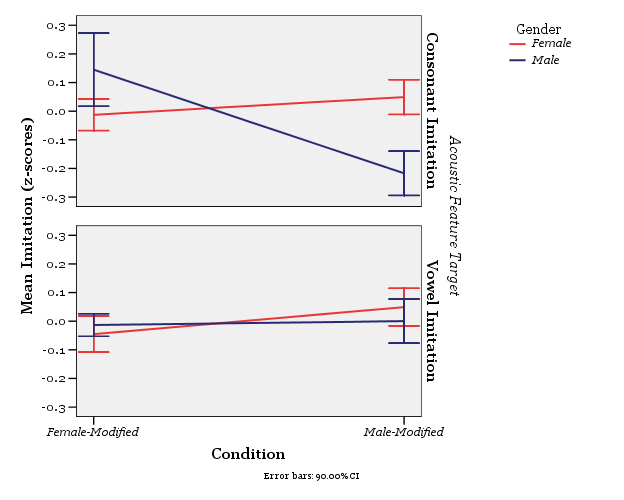
Figure 2. The two panels show degree of imitation by gender and acoustic feature. In the top panel, we see that men imitate the female voice (i.e. positive z-scores in the Female-Modified Condition), but diverge from the male voice (i.e. negative z-scores in the Male-Modified Condition). Women, on the other hand, imitate the male voice, but do not imitate the female voice. Vowel imitation is shown in the bottom panel. The graph indicates that women imitate in the male-modified condition, but do not in the female-modified. Men imitate to a very small degree in both conditions.
Why would women imitate men, while men imitate women? We offer two hypotheses to account for these results. It may be that imitation helps people understand the words they hear, or the behaviours they see. Men may imitate women, and vice versa, then, because opposite gender voices are more dissimilar, and therefore harder to understand. Alternatively, it may be that people imitate in order to show certain kinds of social relationships with people. For example, there is evidence that if we view someone as more socially desirable, we are more likely to imitate them. In this experiment, it is possible that the participants were predominantly heterosexual. Their sexual preference may therefore have influenced which model talker they found more socially appealing, which in turn determined their direction of imitation.