Abby Kaplan - abby.kaplan@utah.edu
Linguistics Dept., University of Utah
Languages & Communication Bldg.
255 S Central Campus Dr., Rm. 2300
Salt Lake City, UT 84112
Popular version of paper 2aSC33
Presented Tuesday morning, May 24, 2011
161st ASA Meeting, Seattle, WA
This experiment studied whether some sounds are 'harder' to say than others – a popular idea, both among linguists and among laypeople, but one that is very difficult to test. The experiment involved having subjects drink a moderate amount of alcohol and then recording their speech, in the hopes that drunken speech would be 'lazier' – that is, that people would tend to say more 'easy' sounds while they were drunk. The results show that drunken speech has a narrower range of sounds than sober speech does; this is consistent with the idea that people tend to say easier sounds when they're drunk. However, the results are also surprising: the sounds produced in drunken speech are not always the same as the ones that linguists usually think of as 'easy'.
Intuitively, it seems obvious that some sounds are harder to pronounce than others. Sometimes, this is just an illusion that comes from the fact that sounds in your native language seem easier than sounds in other languages. For example, the 'th' sound in words like 'think' is quite rare in the world's languages, and it is often difficult for people learning English, but English speakers generally have no trouble with this sound. On the other hand, the sound of French 'u' (a high front rounded vowel) is often hard for English speakers, but not for French speakers.
But it's also possible that some sounds are inherently harder than others. Linguists have suspected for a long time that some sound patterns involve substituting an 'easy' sound for a 'hard' sound. For example, in some languages, the sound [p] is pronounced as a [b] when it is between two vowels; this happens in Korean and Malayalam, among many other languages. Linguists have suggested that this happens because during [p], the vocal folds don't vibrate, but they do during [b] and during vowels. So instead of going to the trouble of stopping the vibration and then starting it up again in a word like 'kapang' (Korean for 'briefcase'), speakers of these languages produce vibration all the way through, saying 'kabang' instead.
Other languages have a related pattern where the sound [b] is pronounced as [v] (or another sound similar to [v]) between two vowels. There are variations on this pattern in many languages, from Spanish to Ancient Hebrew. Linguists have suggested that this happens because a speaker's lips have to be completely closed to say a [b], but only partly closed to say a [v]. Since the speaker's lips are already open during vowels, it's less trouble to bring them partway together and say 'save' (Spanish for 'he knows', with a [v]-like sound) than it is to bring them all the way together and say 'sabe'.
Both of these explanations seem plausible; the problem is that they haven't been tested directly. In other words, we don't know that [b] is really easier between vowels than [p] is; we only think so. The goal of this experiment was to test whether [b] really is easier than [p].
The people who participated in this experiment were recorded reading a list of words in two separate sessions: once while sober, and once while intoxicated. For the intoxicated recording, they drank a measured amount of alcohol (equal parts vodka and orange juice) until their blood alcohol content was between .10 and .12. (This is just above .08, the legal limit for driving in the United States.)
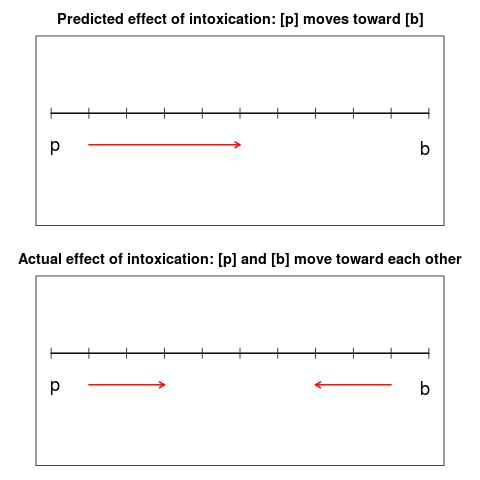
The words that the subjects read contained [p]s and [b]s (or related sounds) between vowels: words like 'epic' and 'cabin'. I predicted that in drunken speech, [p] would sometimes turn into [b] and [b] would sometimes turn into [v], whereas this would not happen as much in sober speech. But, as illustrated in figure 1, this is not what actually happened. Although the subjects did pronounce more of their [p]s like [b]s when they were intoxicated, they also pronounced more of their [b]s like [p]s! (There was a similar effect for [b] and [v].) In other words, the distance between [p] and [b] shrank in drunken speech.
Figure 1. Predicted and actual effects of drunken speech on the pronunciation of [p] and [b].
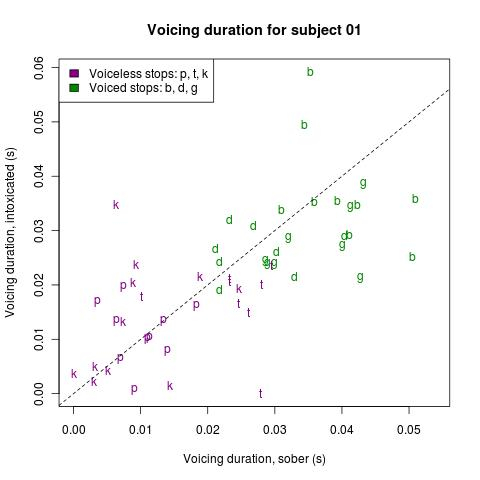
Figure 2. Comparison of voiceless stops ([p], [t], [k], in purple) and voiced stops ([b], [d], [g], in green) in sober and drunken speech by subject 01.
Figure 2 illustrates what this looked like for subject 01. Every data point shows the subject's pronunciation of one word; for example, the [k] in the top left of the graph represents the subject's pronunciation of the word 'ticket'. The x-axis shows voicing duration (i.e., how long the speaker's vocal folds vibrated during the consonant) when the subject was sober, and the y-axis shows voicing duration when the subject was intoxicated. The sounds shown in purple - [p], [t], and [k] - are mostly at or above the dashed line, which means that these sounds tended to have slightly more vibration of the vocal folds in drunken speech. In other words, these sounds were more like [b], [d], and [g] in drunken speech; this is the expected effect. But the sounds shown in green – [b], [d], and [g] – are mostly below the dashed line, which means that these sounds tended to have less vibration of the vocal folds in drunken speech. In other words, these sounds were more like [p], [t], and [k] in drunken speech; this is the unexpected effect.
This experiment confirms the well-known observation that drunken speech is different from sober speech. In addition, these results demonstrate a feature of drunken speech that has not been documented before: the overall range of sounds that people pronounce is smaller in drunken speech than in sober speech.
If drunken speech really does involve saying `easier' sounds, then these results are a challenge for what linguists have traditionally believed about the sound patterns described above. These results suggest that neither [p] nor [b] is easier to pronounce between vowels, but rather that some sound intermediate between the two is easier than both. If it's not true that [b] is easier to say between vowels than [p], then there must be some other reason languages replace [p] with [b] in this context.
An alternative interpretation of this experiment is that drunken speech isn't actually 'easier' than sober speech, and so these results don't tell us anything about which sounds are easier to pronounce than others. One important goal for future research is to try other methods of studying 'easy' and 'hard' sounds, and see whether the results of those methods are consistent with the results of this experiment.