Lisa A. Heimbauer – lisa.heimbauer@gmail.com
Michael J. Beran – mjberan@yahoo.com
Michael J. Owren – owren@gsu.edu
Department of Psychology and Language Research Center
Georgia State University
P. O. Box 5010
Atlanta, GA 30302-5010
Popular version of paper 2aAB9
Presented Tuesday, November 1, 2011
162nd ASA Meeting, San Diego, CA
There has been much debate within the language research community about whether the ability to perceive speech is uniquely human. One view, that “Speech is Special” proposes that both speech production and speech perception are uniquely human abilities (Liberman, 1982). However, because some studies have revealed that some nonhumans can distinguish between various elements of speech (Kuhl & Miller, 1975; Kuhl & Padden, 1982, 1983; Kojima & Kiritani, 1989; Kojima, Tatsumi, & Hirose, 1989), others have argued that auditory perception capabilities of humans and nonhumans are not fundamentally different. Until recently, however, none of the research with animals had investigated their ability to solve the perceptual problems that humans solve when listening to meaningful words in altered and distorted forms.
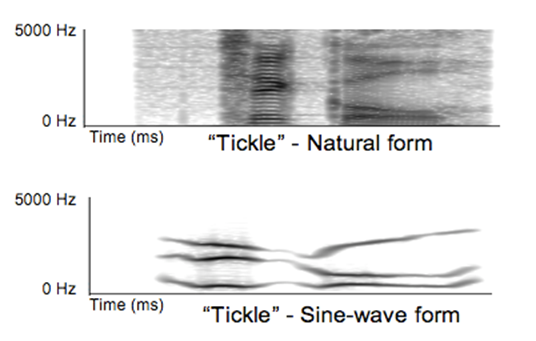
To investigate a nonhuman’s ability to perceive distorted speech, we previously tested a language-trained chimpanzee (Pan troglodytes), named Panzee, with sine-wave speech. Sine-wave speech typically consists of just three individual tones, each modeled on a vocal-tract resonance (formant). This synthesized form is highly impoverished relative to the rich frequency content of speech, has been described as high-pitched whistling, and sounds quite unnatural (audio1, audio2). When comparing a word in natural form to one in sine-wave form (see Fig. 1), it is easy to see why sine-wave speech is considered to preserve phonetic sound properties only in abstract form (Remez et al., 2009). Results revealed that this animal was, indeed, able to recognize familiar English words when they were in this altered form (Heimbauer, Beran, & Owren, 2011).
FIG. 1. Spectrograms of the word “tickle” in natural and sine-wave T123 form.
Panzee’s performance with sine-wave speech has provided the first evidence of human-like performance with word-length distorted speech by a nonhuman. This result suggests that apes and humans may have similar speech-perception capabilities. However, it is difficult to know whether the underlying mental processes are therefore similar in the two species. We conducted the current experiment in order to take a closer look at what Panzee may be “tuning into” when hearing sine-wave speech. Previous research (Remez, Rubin, Pisoni, & Carrell, 1981) has shown that human listeners are most successful in identifying sine-wave speech when the first two tones (T12) or all three tones (T123) are present. Performance is notably worse when either the first or second tone is absent (i.e., T23 and T13). This result most likely occurs because the first two tones together provide more of the information about sound patterning over time than any other combination. Our experiment tested Panzee and 13 human participants with sine-wave words in these four forms (see Fig. 2).
FIG. 2. Spectrograms of the word “tickle” in T123, T12, T23, and T13 sine-wave form.

Panzee is a 25-year-old female, who is housed at the Language Research Center at Georgia State University. She was raised exclusively by humans from eight days old, and treated as a human infant would be. She routinely heard meaningful speech and was also taught to use symbols and photos to communicate (see Fig. 3). The result is that Panzee can recognize and identify approximately 130 English words by choosing a corresponding symbol or photo (Beran, Savage-Rumbaugh, Brakke, Kelley, & Rumbaugh, 1998).
FIG. 3. The chimpanzee subject, Panzee, at about 33 months of age.

In this experiment, Panzee heard 24 of her familiar words (see Table 1) in either natural or sine-wave form, with the words presented in randomized order for a total of 96 trials per session. On each trial, she used a joystick to select the corresponding photo from four alternatives presented simultaneously on a computer screen (see Fig. 4). A complete test required two sessions, with 12 of the words presented four times each in natural form and the other 12 words once in each of the sine-wave forms T123, T12, T23, and T13 (audio3, audio4). In the second session, on a different day, she heard the words with these conditions reversed (see Table 1, bottom of page). Panzee was tested over six days in all, with 288 total sine-wave trials that included hearing each word three times in the four different forms. Panzee did not receive any feedback for correct or incorrect choices, ensuring that her responses were based solely on her experience with natural speech. However, a randomized computer tone, played after every three to four trials, prompted the human experimenter to give Panzee a piece of preferred food as a reward for working during sessions. Within a session, 16 words in natural form and 8 words in synthesized form were presented in four randomized blocks, for a total of 96 trials. Typically, a session lasted for 20 to 30 minutes.
FIG. 4. Panzee working at an experimental computer task.

Thirteen university students were tested with the same stimuli for comparison. They were first familiarized with the words in natural form while seeing corresponding, labeled photographs, and also listened to and identified a sample of sine-wave speech before starting testing. In the actual experiment, the participants used headphones to listen to and transcribe the same two sets of words used with Panzee. These stimuli were again randomized, but here presented in two consecutive, counter-balanced blocks within a single session.
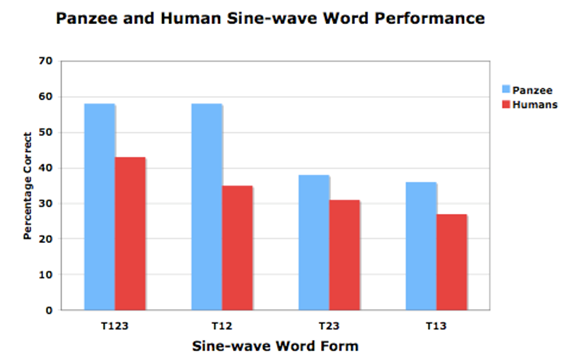
Panzee’s percentage correct for the natural words was 87%, which is consistent with her performance when tested annually. Human performance with natural words was 99.7%. Results for sine-wave word identification revealed that both Panzee and the humans were significantly better at identifying sine-wave versions when the first two tones were both present, showing lower performance when one of these tones was absent (see Fig. 5). This similarity indicates that Panzee is not only able to recognize words in this fundamentally distorted synthetic form, but that she may be attending to the same acoustic features that humans listen to when they hear sine-wave speech. The findings reinforce the fact that experience is a key factor in speech perception, and that unique, biologically specialized mechanisms may not have played a critical role in speech evolution. The results suggest that the common ancestor of chimpanzees and humans may have had the capability to perceive speech-like sounds before the evolution of speech, and that early humans were taking advantage of this latent ability when speech did eventually emerge.
FIG. 5. Percentage correct on sine-wave word trials for Panzee and human participants.
References:
Beran, M.J., Savage-Rumbaugh, E. S., Brakke, K. E., Kelley, J. W., and Rumbaugh, D. M. (1998). Symbol comprehension and learning: A “vocabulary” test of three chimpanzees. Evolution of Communication, 2, 171-188.
Heimbauer, L. A., Beran, M. J., and Owren, M. J. (2011). A chimpanzee recognizes synthetic speech with significantly reduced acoustic cues to phonetic content. Current Biology, 21, 1210-1214.
Kojima, S., and Kiritani, S. (1989). Vocal-auditory functions in the chimpanzee: Vowel perception. International Journal of Primatology, 10, 199-213.
Kojima, S., Tatsumi, I. F., and Hirose, H. (1989). Vocal-auditory functions of the chimpanzee: Consonant perception. Human Evolution, 4, 403-416.
Kuhl, P. K., and Miller, J. D. (1975). Speech perception by the chinchilla: voiced-voiceless distinction in alveolar plosive consonants. Science, 190, 69-72.
Kuhl, P. K., and Padden, D. M. (1982). Enhanced discriminability at the phonetic boundaries for the voicing feature in macaques. Perception & Psychophysics, 35, 542-550.
Kuhl, P. K., and Padden, D. M. (1983). Enhanced discriminability at the phonetic boundaries for the place feature in macaques. Journal of the Acoustical Society of America, 73, 1003-1010.
Liberman, A.M. (1982). On finding that speech is special. American Psychologist, 37, 148-167.
Remez, R.E., Dubowski, K.R., Broder, R.S., Davids, M.L., Grossman, Y.S., Moskalenko, M., Pardo, J.S., and Hasbun, S.M. (2009). Auditory-phonetic projection and lexical structure in the recognition of sine-wave words. Journal of Experimental Psychology: Human Perception and Performance, 37, 968-77.
Remez, R. E., Rubin, P. E., Pisoni, D. B., and Carrell, T. D. (1981). Speech perception without traditional speech cues. Science, 212, 947-949.
TABLE 1. Words used as test stimuli, which were presented in both natural (“NL”) and sine-wave (“SW”) forms.
Word |
Session 1 |
Session 2 |
Apricot |
SW |
NL |
Banana |
SW |
NL |
Blueberries |
NL |
SW |
Bubbles |
SW |
NL |
ColonyRoom |
NL |
SW |
Gorilla |
NL |
SW |
Lemonade |
NL |
SW |
Lookout |
SW |
NL |
M&M |
NL |
SW |
Melon |
SW |
NL |
MushroomTrail |
NL |
SW |
ObservationRoom |
NL |
SW |
Orange |
SW |
NL |
OrangeDrink |
SW |
NL |
OrangeJuice |
NL |
SW |
Pineneedle |
NL |
SW |
PlasticBag |
NL |
SW |
Potato |
NL |
SW |
Sparkler |
SW |
NL |
Sugarcane |
NL |
SW |
Surprise |
SW |
NL |
Tickle |
SW |
NL |
Water |
SW |
NL |
Yogurt |
SW |
NL |