Esteban Maestre - esteban@ccrma.stanford.edu
Center for Computer Research in Music and Acoustics, Stanford University
660 Lomita Drive
Stanford, CA 94350
Music Technology Group, Universitat Pompeu Fabra
138 Roc Boronat
Barcelona, Spain 08018
Popular version of paper 3aMU2
Presented Wednesday morning, November 2, 2011
162nd ASA Meeting, San Diego, Calif.
Despite recent advances in computer simulation of musical instruments, there is a widespread feeling that instrumental sound synthesizers still fail to faithfully reproduce the natural-sounding characteristics of human performance, thus limiting their potential expressive capabilities when used for automatic generation of sound from a written score (i.e., when used in automatic performance contexts). This is especially true for instruments that produce sound through continuous inflections of their input controls (often called excitation-continuous instruments), like it is the case of bowing motion in violins or blowing pressure in wind instruments. Because of difficulties inherent to analyzing and simulating instrumental playing technique, synthetic sound often results far from believable when dealing with instruments that require continuous input controls. In fact, the more convincing results achieved by excitation-instantaneous (e.g., percussion or piano-like) virtual instruments when used for automatic performance directly derive from the rather simpler characteristics of sound-producing actions taking place during performance.
Is something missing in instrumental sound synthesis?
Rather than to explicitly include the analysis and emulation of instrumental playing technique, research efforts in computer generation of instrumental sound have traditionally been more devoted to modeling the acoustical properties of musical instruments. This has been achieved either by attending to the physical characteristics of sound production mechanisms (leading to what is known as physical models) or by focusing on how sound is perceived (deriving into the commonly referred to as spectral models). While physical models aim at constructing a mathematical representation of the physical instrument and its actual behavior as a sound-producing object, spectral models are only based on the observation of sound properties across extended audio recordings that span different playing contexts.
Since they are constructed to behave like the real instrument, physical models require input controls that resemble those used in real performance. In automatic performance, this feature constrains their use to those cases in which it is possible to synthesize convincing input controls from a written score. Hence, despite the flexibility a priori offered by physical models, only instruments presenting rather simple control characteristics (e.g., excitation-instantaneous instruments) enable the automatic generation of input controls which can be successfully used as input to the sound synthesis engines.
With regard to spectral models, their controllability gets often restricted by a palette of sound transformation (or morphing) patterns directly learnt from analyzing a database of representative audio snippets. Spectral models are often applied within concatenative frameworks: given a written score, synthetic sound is generated by selecting, transforming and concatenating existing audio samples. Because of the discrete nature of the sample database and its annotations, the domain and quality of sound transformations get limited by the extent of the initial set of recordings, leading to a reduced control flexibility that generally results in audible timbre discontinuities especially at sample-to-sample concatenation junctions. Again, more convincing results are achieved for excitation-instantaneous instruments, due to the fact that discrete information appearing in a written score is a much better match for selecting, transforming, and concatenating a discrete set of individually triggered sounds.
In an attempt to significantly improve the naturalness of synthetic sound, and in particular for excitation-continuous instruments, it becomes necessary to explicitly investigate and represent basic performance resources (e.g., dynamics, articulation, etc.) from a playing technique perspective. In other words, it is crucial to also address the question of how instruments are played and not only how instruments sound. Then, how to face the study of instrumental playing from a computational perspective? Although partial information on performance technique can be extracted by only studying sound recordings and applying specialized audio analysis methods, exploring the actual input controls to the instrument (e.g., by measuring detailed bowing motion or blowing pressure during real performance) appears as the most direct and unequivocal method. Indeed, thanks to recent improvements in both size and accuracy of different sensing technologies and devices, non-intrusive capturing techniques start to become affordable means for reliably measuring instrument controls in real performance scenarios.
This work deals with the acquisition, analysis, modeling, and synthesis of bowing gestures in violin performance. Within excitation-continuous instruments, the violin is considered among the most expressive and difficult to play. Provided that state-of-the-art motion capture and sensing techniques can now be used to accurately measuring bowing controls in real playing, the violin represents an optimal opportunity to computationally explore the challenging issue of explicitly introducing performance technique into sound synthesis.
Capturing the essence of violin bowing technique
In order to observe and analyze bowing technique in detail, it is necessary to identify and measure the bowing controls that are directly involved in sound production. The main three bowing controls available to the violinist during performance are the bow transversal speed, the bow pressing force, and the bow-bridge distance. Bow speed and bow-bridge distance are acquired using a commercial motion capture device. One miniature sensor providing position and orientation is attached to the violin body, making possible to infer the eight string ends with great accuracy. Bow hair ribbon ends are tracked in a similar manner by attaching another sensor to the bow stick. From string and hair ribbon ends, bow transversal velocity and bow bridge distance are computed in real time. Simultaneously, bow pressing force is extracted by using a deformation sensor placed on the inner side of the hair ribbon. An illustrative video of a capture test can be watched here:
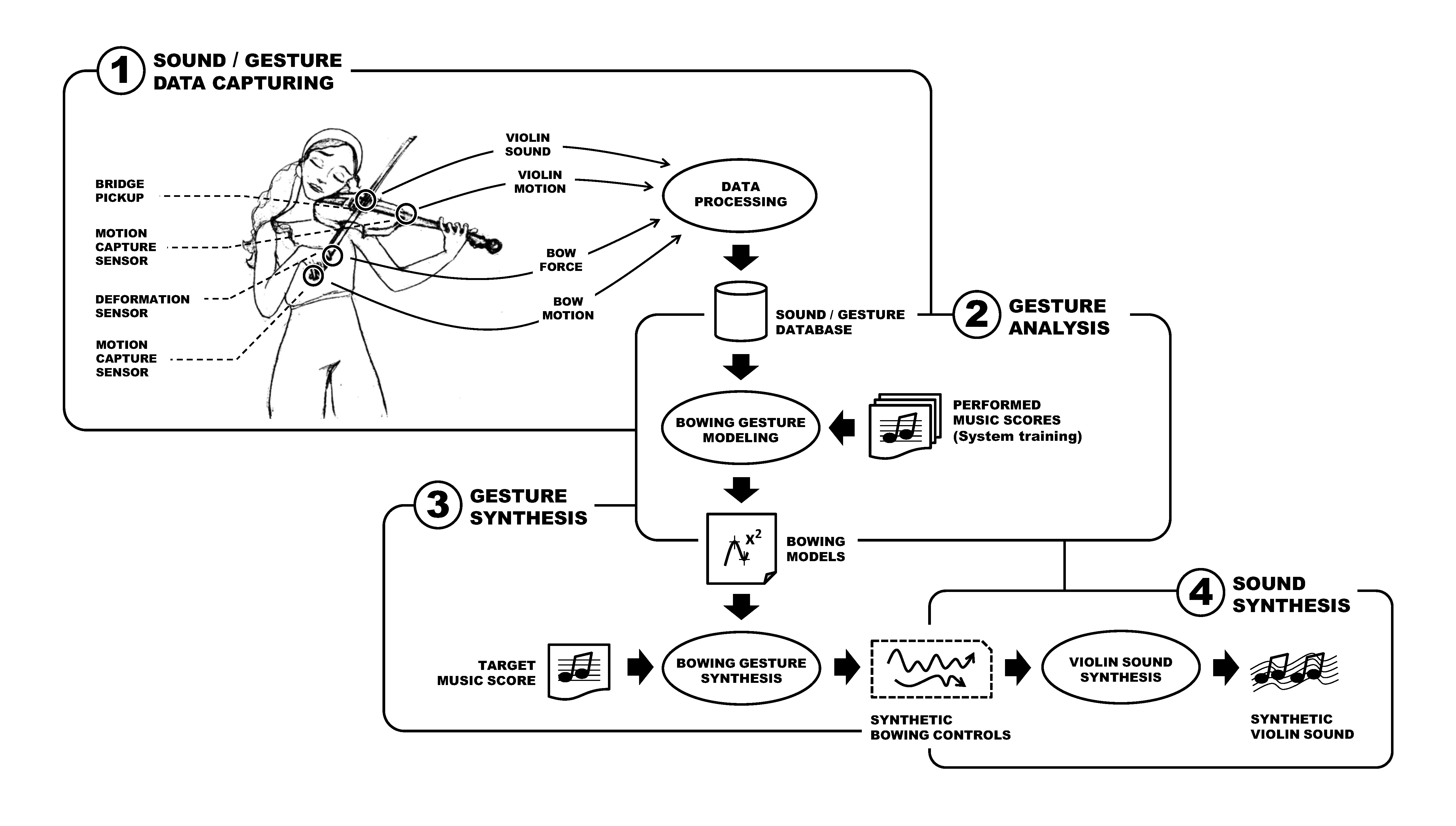
"Figure 1. Framework for bowing data capturing, analysis and synthesis."
Together with the produced sound, motion and force data are synchronously acquired, processed, and stored in a multi-modal database containing long recordings of real performances. The database, which covers a representative set of articulations, dynamics, and note durations in different playing contexts, contains the raw information from which the essence of the players's bowing technique is modeled. From the raw bowing control data and the database annotations (the latter extracted from the musical scores performed during the recordings), techniques for numerical representation of motion curves are applied to obtain a flexible, yet robust characterization for the different bowing techniques.
Through statistical analysis, a generative model is constructed as the central part of tool for synthesizing continuous bowing controls from a new, unknown written score. Because of the malleability of synthesized bowing controls, it is straightforward to let the system adapt bowing characteristics to different playing contexts imposed by a new musical score, in a similar manner as a human would do. Thanks to the modeling framework, it is now possible to insert a virtual performer between the musical score and the virtual instrument, as it is represented in Figure 1.
As the main factor motivating this work, sound synthesis already benefit from the availability of continuous controls generated automatically, as illustrated in Figure 2. Regarding physical models, the realism of obtained performances gets significantly improved even when using a highly simplified virtual instrument model. The flexibility of sample-based spectral synthesis models is improved thanks to the greater instrument control awareness exhibited by enhanced sample retrieval, transformation, and concatenation. An example of synthetic sound using spectral models can be heard here:
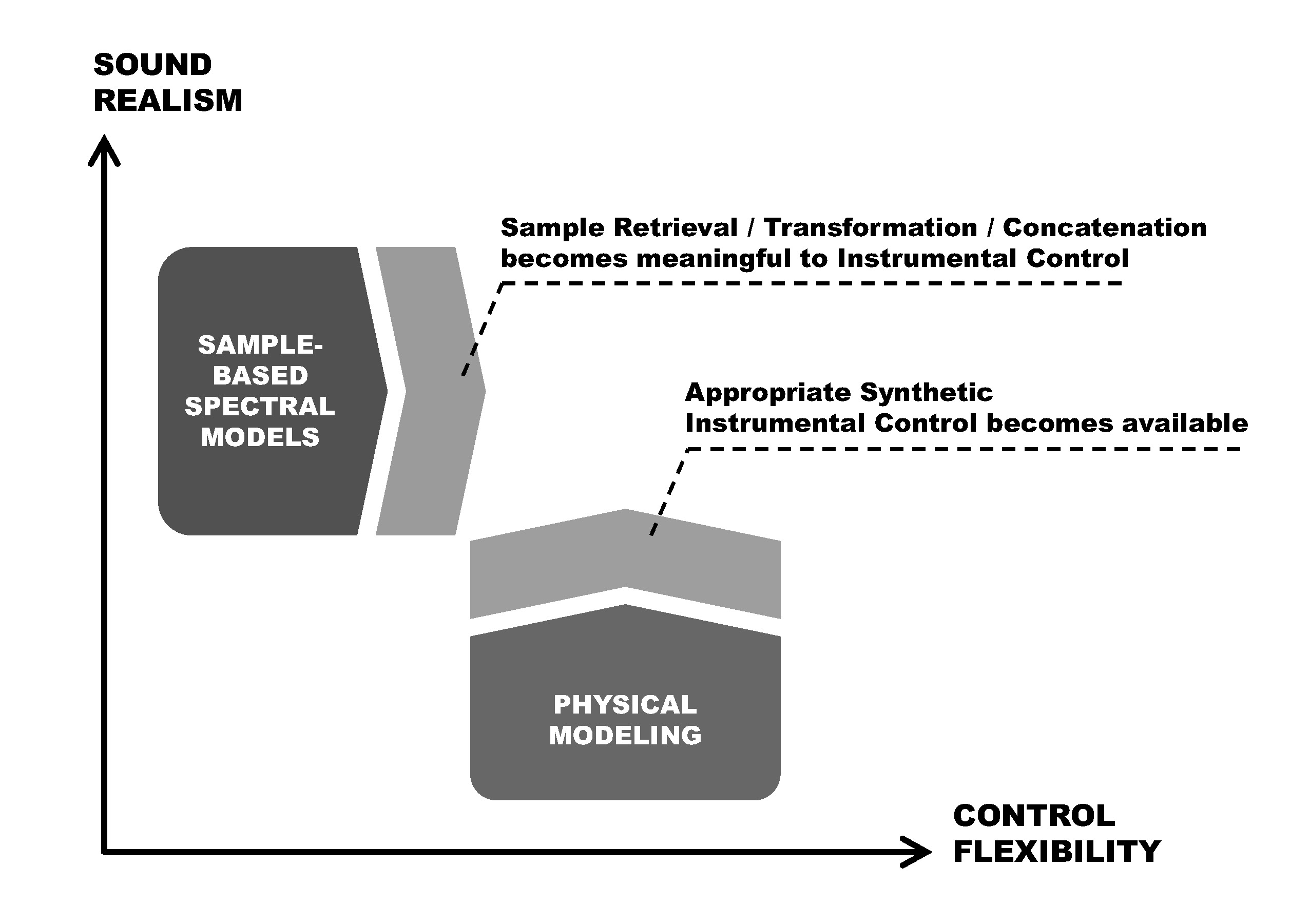
"Figure 2. How instrumental control models are to improve sound synthesis."
Future directions
There is still a long path to walk before a computer performance can be comparable to that of a human, but obtained results show a promising line of research full of interesting endeavors. Prominent challenges include the incorporation of left-hand articulations, embedding the model with capabilities to morph between different virtual violinists and different virtual violins, and carrying out initial experiments towards higher level expressive control. Simultaneously, a pilot study is being performed on blowing pressure in recorder performance.
Through an on-going collaboration between Universitat Pompeu Fabra, McGill University, and Stanford University, the work presented here is to be extended to string quartet performance with a focus that includes the study of interaction phenomena. In the future, the use of computer-aided instrument control interfaces may be of great value research in social interaction, musical training, or even physical rehabilitation.
Acknowledgement
The author wants to thank Jordi Bonada, Merlijn Blaauw, Alfonso Pérez, and Enric Guaus for their implication on this project.