Bernd T. Meyer – bmeyer@icsi.berkeley.edu
International Computer Science Institute,
Berkeley, Calif., USA
Medical Physics, Institute of Physics,
Univ. of Oldenburg, Germany
Popular version of paper 2pSCa2
Presented Tuesday afternoon, Nov 1, 2011
162nd ASA Meeting, San Diego, Calif.
Have you ever hung up on an automated voice that asked you to repeat what you just said because it had difficulties understanding you? Why is it that automatic systems often struggle in speech recognition, yet human listeners do an amazing job of understanding what someone else said? To find an answer to this question, we compared speech recognition of humans and machines, with the ultimate goal of learning from the biological blueprint and improving automatic recognition. For the comparison, we asked participants to listen to a series of nonsense words in noise and report what they understood.
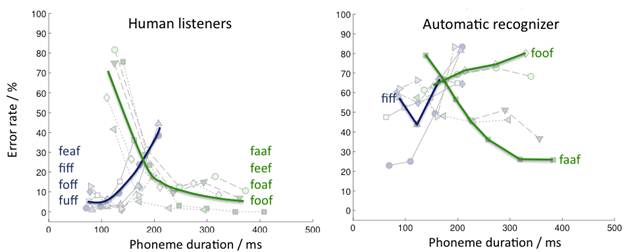
We then took the same words and had a machine try to recognize it as well. Since we used nonsense words, listeners could not use contextual knowledge, as they usually would (e.g., by making assumptions about what someone is talking about given the “acoustic scene” they are in). Still, humans far outperformed the automatic recognizer; in very noisy conditions, listeners correctly identified three of four nonsense words correctly, while the machine only recognized one of three. We then looked at specific differences between subjects and automatic classifiers, and observed that humans rely on the changes of speech over time, i.e., the temporal context plays a major role in our auditory system. These patterns were not observed for an automatic recognizer which was tested in the same noise conditions (Fig. 1).
This result suggests that additional information about speech and its changes over time should be used for next generation systems for automatic speech recognition.
Figure 1: When human listeners were asked to identify the central vowel in nonsense utterances, two groups of vowels clearly emerged when the error rates were analyzed with respect to the duration of the vowel. This shows that our auditory system pays attention to temporal ascepts of speech. The same result was not found for an automatic recognizer, which suggests to use this kind of information in future recognition systems.