
Ramani
Duraiswami - ramani@umiacs.umd.edu
Richard O. Duda, V. Ralph Algazi, Larry Davis, Nail Gumerov, Qing-Huo Liu, Shihab Shamma, Howard Elman, Rama Chellappa, Yiannis Aloimonos, S.T. Raveendra
Institute for Advanced Computer Studies, University of Maryland,
College Park, MD, 20742
Popular version of paper 4aPP11
Presented Thursday Morning, 11:15 a.m., December
7, 2000
ASA/NOISE-CON 2000
Meeting, Newport Beach, CA
Work supported by NSF.
There are many scientific, commercial and entertainment applications for 3-D or spatial sound. An ideal virtual spatial audio system would produce the illusion of hearing sounds as if you were actually present in the room. The 3-D PC-soundcards and the home theater systems that are now available are able to place sounds far to the left, right, and even behind the listener. However, accurate and controllable placement of sounds in all three dimensions -- left and right, up and down, near and far -- is beyond the ability of current technology. All three dimensions must be controlled to produce the virtual audio needed for virtual reality. Our research is directed at making this possible.
Hearing scientists have shown that - in
principle, at least - it is possible to make sounds appear to come from any
desired location. Furthermore, this can be done using only two signals - the
sound reaching each of the ears. By
properly controlling the sounds sent through headphones to the left and the
right ears, the experience of being in a 3-D sound space can be reproduced. By using clever digital signal
processing techniques, audio engineers have shown that the same effects can be
produced using only two loudspeakers.
The secret to creating these effects emerged
from careful study of the cues that humans use to locate a sound source. The most familiar cue is the so-called
interaural time difference, the difference in the times at which the sound waves
coming from a source reach our two ears.
However, the interaural time difference is by no means the only cue. Although it accounts for much of our
left/right perception, it does not explain our up/down or our near/far
perception.
It turns out that we use not only the sound
traveling directly from the source to our ear canals, but also the sound that
reaches us via other more indirect paths, after being scattered off our external
ears, heads, and bodies, as well as walls, floors, and other surfaces in the
surrounding environment. It is this
scattering process that endows the received waves with cues that the brain
deciphers and processes to locate the source.
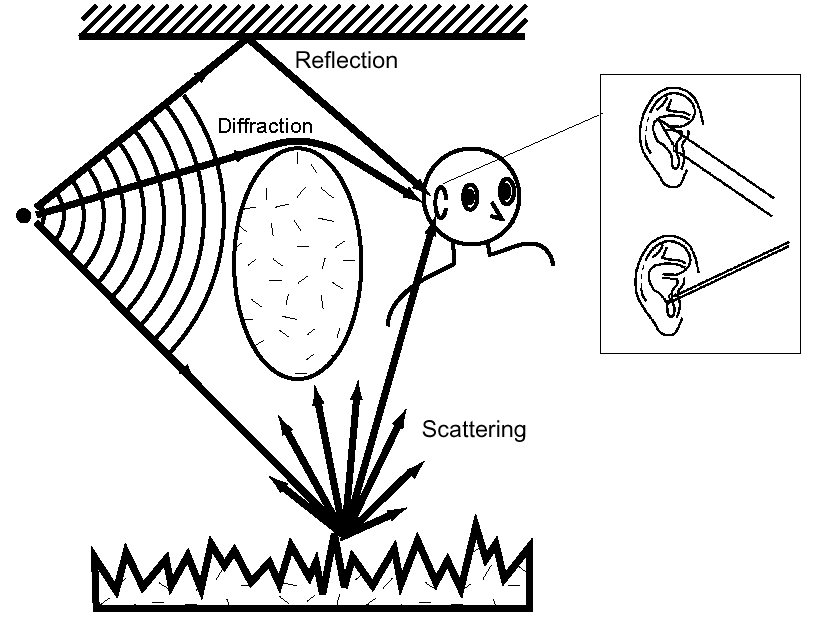
Fig. 1: Sound from a source that
reaches our ears includes both the sound that arrives along a direct path and
sound that is scattered by the environment and our external ears and body. This
scattering process amplifies or attenuates different frequency components,
producing cues that enable our brains locate the source.
When a sound wave is scattered off an object,
its behavior is governed by the ratio of the object size and the wavelength of
the sound. When the object size is much larger than the wavelength, the sound
bounces off like a ray of light hitting a mirror. However, when the object size
and the wavelength of the sound wave are comparable, the scattered wave is much
more complex. Furthermore, the various components of the sound that reach the
ear via different paths interact with one another. For ordinary sounds that
contain many different frequencies, the result is a change in the balance
between different frequencies that we are subconsciously able to attribute to
the location of the source. The
process by which the brain does this localization is a subject of intense
research by neuropsychologists.
The function that encodes the relative
amplification or attenuation of the sound at a particular frequency is called
the "Head Related Transfer Function," and is often abbreviated as the HRTF. The secret to rendering virtual audio
accurately is to obtain the HRTF accurately. However, there is a major complication.
HRTFs are different for different people. Because we all have different sized
and shaped ears, heads and bodies, we all have different HRTFs. Just as we need our own customized
eyeglasses to see properly, we need our own customized HRTFs to hear spatial
sound properly. Failure to account
for individual differences leads to problems such as elevation errors and high
rates of front/back confusion.
Furthermore, for a true perception of a
localized source, the cues must change with the motion of the listener. If they
do not change properly, the listener can become confused, and can even
experience the sound as coming from within his or her head. Thus, the HRTF must not only be
customized to the individual listener, but it must also change correctly when
the listener moves.
Our research is directed at finding effective
ways to solve these two key problems: (a) quick and accurate determination of
individual HRTFs, and (b) quick and accurate ways to modify the HRTFs
dynamically in accordance with a listener's movements, including changes that
arise from changes in the listener's posture. In both cases, we want to take
advantage of advances in computer vision research and technology to solve these
problems.
In recent years, it has become possible to
use computers to determine many physical properties of objects from digital
video, using developments in powerful computer vision methods. To measure
individual HRTFs, we will use computer vision techniques to obtain accurate 3-D
surface models of a person's torso, head, and ears. We will then calculate the HRTF by using
numerical methods to solve the basic equations of physics that govern the
propagation of sound waves. We
expect that this approach will be much more rapid, accurate and convenient than
the acoustic methods currently used to measure HRTFs. In spite of the massive computation
required, advances in high-performance computing now make such an approach
possible. Additionally, part of our research will be devoted to developing even
faster computational methods.
To modify the HRTFs dynamically, we will use
computer vision techniques to track people as they move, and to modify the HRTF
accordingly. In our initial work,
we will neglect any possible effects of the limbs and torso, and will focus on
the changes that stem solely from head translations and rotations. However, we also will decompose the
HRTFs into parts that separately account for the contributions of different
parts of the body. This decomposition will provide an ability to account for the
important effects of postural changes.
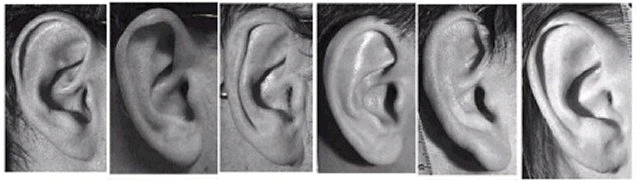
Fig.2: Our ears have extremely different shapes, resulting in very different sound scattering characteristics, and consequently, very individual HRTFs.
We believe that this research will lead to
effective methods for measuring individual HRTFs and modifying them dynamically,
thereby providing both the static and the dynamic cues that will produce true
3-D virtual audio. Such an
accomplishment will be a major advance in the use of information technology in
virtual audio.
An overview of our long-term project, as well as preliminary results that compare the numerical techniques to be used with analytical and experimental results for scattering from simple shapes, will be presented at the conference.