
Cynthia G. Clopper- cclopper@indiana.edu
David B. Pisoni
Speech Research Laboratory
Department of Psychology
Indiana University
Bloomington, IN 47405
Popular version of paper 4aSC6
Presented Thursday morning, May 27, 2004
147th ASA Meeting, New York, NY
Introduction
The way someone talks can tell us a lot about them. For example, it is usually quite easy to determine a stranger's gender when talking to them on the phone. We can also make guesses about a person's age, socioeconomic status, race, ethnicity, level of education, hometown, and native language based only on his or her speech. The study of the social information carried by speech has traditionally been the domain of sociolinguistics. However, speech scientists have recently begun to examine the role of this kind of social information in spoken language processing. The goal of the Nationwide Speech Project (NSP) was to compile a large amount of recorded spoken language for use in future projects on the perception of regional dialects of American English. The NSP is a collection of audio recordings of people from different parts of the United States. Each person was recorded for nearly an hour while reading aloud and while talking to the experimenter about his or her hometown, hobbies, and travel experiences.
Design of the NSP
Before we recorded the NSP speech materials, we needed to consider a number of factors related to the talkers, the recording equipment and conditions, and the kinds of speech that we wanted to include. Table 1 shows some examples of each of these three components of any collection of spoken language.
| Factor | Examples |
| Talker Demographics | age, gender, socioeconomic status, race, ethnicity, level of education, residential history, linguistic experience |
| Recording Conditions | analog or digital tape recordings, telephone recordings, digital recordings in a sound-proof booth |
| Speech Materials | conversational speech, interview speech, read speech, babytalk, singing, whispering, shouting |
While language can vary due to all of the talker demographic factors shown in Table 1, we decided to hold the variables related to age, socioeconomic status, race, ethnicity, level of education, and linguistic experience constant in order to focus on variation due to regional origin of the talkers. Therefore, all of our talkers were white, middle-class, college-educated 18-25 year olds who were monolingual native speakers of American English. The variables we were interested in for the current project were gender and residential history: the NSP includes recordings from five males and five females from each of six dialect regions of the United States, for a total of 60 talkers. Figure 1 is a map of the United States showing the six dialect regions and the hometowns of each of the 60 talkers. Males are indicated by black circles and females are indicated by white circles.
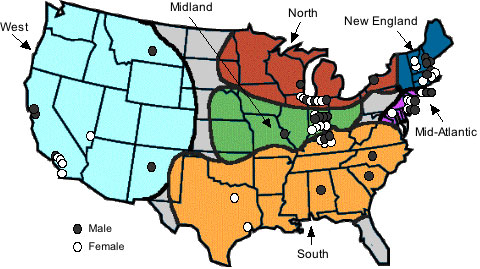
Figure 1. Map of the six dialect regions and 60 talkers included in the NSP.
While recording people talking in comfortable settings such as their home or a restaurant often results in more "natural" speech samples, these recordings are typically poorer in quality and have significant background noise that makes future acoustic analysis of the recordings difficult. We therefore decided to record our talkers in a sound-attenuated booth using high-quality recording equipment. While this may somewhat reduce the "naturalness" of the speech, it allows us to use the recordings in a wide range of projects including acoustic analysis of the speech and presentation of the speech samples to untrained listeners.
It is well known that when people read aloud they often are more conscious of their speech than if they are having a conversation about a topic that they find interesting. Therefore, even in a laboratory setting it is possible to record speech with different degrees of naturalness through the use of different tasks ranging from reading word lists to casual conversations with the experimenter. We decided to limit the speech materials in the NSP to normal speech (as opposed to whispered or shouted speech), but each talker was recorded reading words, sentences, and paragraphs, as well as in conversations with the experimenter. We recorded two types of words: monosyllabic words and multisyllabic words. We also recorded two types of sentences: meaningful English sentences and semantically anomalous sentences. The semantically anomalous sentences were grammatically correct, they just didn't make any sense in terms of their meaning. These word and sentence lists provide us with identical utterances from each talker than can be compared for dialect features. The conversational speech samples allow us to examine more casual utterances in which the talkers may have been paying less attention to their speech. Some examples of the materials are shown in Table 2.
| Materials Set | Examples |
| Monosyllabic Words | mice, dome, bait |
| Multisyllabic Words | alfalfa, nectarine |
| Meaningful Sentences | Ruth has a necklace of glass beads. The swimmer dove into the pool. |
| Anomalous Sentences | Bill knew a can of maple beads. The jar swept up the pool. |
| Interview Speech | Hometown, hobbies, travel experiences |
Results
An analysis of the speech materials we collected for the NSP revealed that the talkers do in fact differ in their speech based on where they are from. This result means that we can use the NSP recordings for a number of projects on the perception of dialect variation, including how listeners make judgments about where strangers are from and the effects of dialect differences on language processing in noisy conditions.
Below are some examples of important features of the speech of talkers from different parts of the United States. Click on the links to hear examples of each feature.
New England: One prominent feature of New England speech is a change in the vowel in the word cat. For example, in the sentence Old metal cans were made with tin the word cans sounds almost like kens.
Mid-Atlantic: One feature of Mid-Atlantic speech, particularly in New York City and New Jersey, is a change in the vowel in the word caught. In the sentence I ate a piece of chocolate fudge. the word chocolate sounds almost like choke-late.
North: One prominent feature of Northern speech is a change in the vowel in the words cot. In the sentence The doctor prescribed the drug the word doctor sounds almost like dactor. Northern talkers also show the same shift in the vowel in cat that the New England talkers do.
Midland: The only prominent feature of Midland speech is a merger of the vowels in the words cot and caught that result in nearly homophonous pronunciations of these two words.
South: One of the most prominent features of Southern speech is a change in the vowel in the word kite. In the sentence We swam at the beach at high tide the words high and tide sound almost like ha and todd.
West: A prominent feature of Western speech is a shift in the vowel in the word boot. For example, in the sentence The super-highway has six lanes the word super sounds almost like sipper. Western speakers also have homophonous pronunciations of the vowels in caught and cot like the Midland talkers.