
Norman Adams - nhadams@umich.edu
and Gregory Wakefield
Electrical Engineering and Computer Science
University of Michigan
1101 Beal Ave.
Ann Arbor, MI 48109
Popular version of paper 5aMU6
Presented Friday Morning, Oct. 21, 2005
ASA/NOISE-CON 2005 Meeting, Minneapolis, MN
News
Query-by-humming (QBH) is a popular and emerging application of music information retrieval (MIR). QBH systems allow a user to search a database of melodic themes by singing or humming, rather than providing artist information or song name. Several systems have been developed, but thus far the systems operate over modest databases, and do not scale well to massive databases.
In this paper, we explore different representations of sung melodies for database retrieval applications. We compare two existing representations, as well as propose a novel representation. Furthermore, we expand the conventional retrieval method to achieve both accurate and rapid retrieval. The approach described below is an important step towards deploying a robust query-by-humming system on the Internet.
Background
There is currently much interest in query-by-example systems within the information retrieval community. These systems search a database using an example that is similar to one or more of the entries in the database. While many query-by-example systems are prototyped over small databases, the goal is to eventually deploy them on the Internet, the most massive of all databases. The overwhelming majority of data available on the internet is not text, but rather sound, image and video, yet contemporary search engines still require users to provide text descriptors, even if they are searching for sound or image data. Query-by-example systems allow the user to search for multimedia content using multimedia queries, without relying on text descriptors or other metadata.
In the MIR community, query-by-humming systems are the focus of many research groups. Consider an individual who has a melody in mind and would like to find the song containing this melody, but cannot remember the name of the tune, nor its composer or performer. A QBH system allows the individual to search a database for the desired song by simply singing, or humming, a portion of the melody.
The question arises of how best to represent, or code, the sung query for the retrieval task. Often, the sung query is transcribed into a sequence of notes. The retrieval is performed by comparing the transcribed query with every theme in the target database and the most similar target themes are returned to the user. However, as we demonstrate below, this representation of casually sung queries yields inferior retrieval performance to other melodic representations. Unfortunately, the melodic representations that yield better performance also yield much slower retrieval. Indeed, there is a well-established tradeoff between accuracy and speed in retrieval applications. As such, we propose an iterative method that achieves both robust accuracy and rapid retrieval.
Methods
All three of the melodic representations that we consider are time series. Each representation consists of a sequence of elements, such as notes. The first representation that we consider is perhaps the most intuitive, a conventional sequence of notes. Using this representation, a short sung query is represented by a sequence of about 10 to 20 notes. Unfortunately, casually sung queries are riddled with performance imperfections such a pitch errors, legato, and scooping. These imperfections, while not necessarily distracting to the ear, render accurate transcription impossible (indeed, it is unclear even how to define an accurate transcription of a casually sung query). In particular, detecting note boundaries is error-prone. As the target database grows, the problems associated with accurate transcription place a severe performance bound on retrieval accuracy. For this reason, we explore two alternative representations of sung queries.
One alternative representation is the smooth pitch contour. This representation is computed by estimating the pitch sung by the user at uniformly spaced intervals in time. Typically this interval is small, yielding a sequence of about 100 to 200 pitches. A sample pitch contour from the main theme of Richard Rodgers’ The Sound of Music is shown in blue in the figure below (the lyrics that accompany this theme are “The hills are alive with the sound of music”). Here is what a sample query, and accompanying pitch contour might sound like.
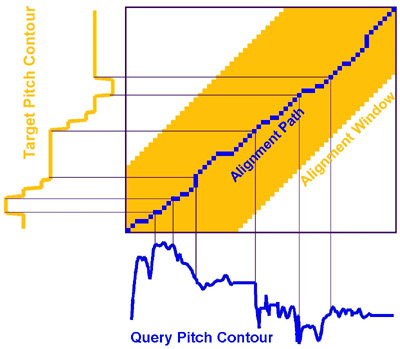 The pitch contour must be compared to all the themes in the target database. This is done by aligning the query contour with each target contour, and computing their similarity. A sample alignment is shown to the right. We found that the contour representation yields considerably better retrieval accuracy, especially for large target databases. Unfortunately, because the contour representation is about 10 times longer than the note representation, it is about 100 times slower than the note representation.
The pitch contour must be compared to all the themes in the target database. This is done by aligning the query contour with each target contour, and computing their similarity. A sample alignment is shown to the right. We found that the contour representation yields considerably better retrieval accuracy, especially for large target databases. Unfortunately, because the contour representation is about 10 times longer than the note representation, it is about 100 times slower than the note representation.
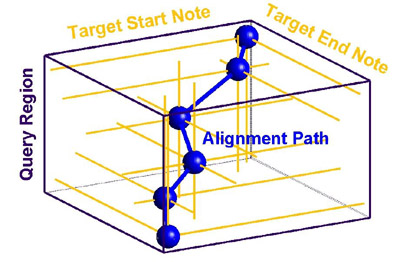 Due to the slow retrieval of the contour representation, we propose a new melodic representation, a sequence of pitch histograms. This representation segments the sung query into several regions based on the pauses between some sung notes. The histogram representation has the advantage of being a very short time series, typically with fewer than ten elements, but has the disadvantage that each element may align with multiple notes in the target theme. This complicates the alignment procedure, for the alignment matrix must now have three dimensions instead of two. A sample alignment is shown to the left. Both in terms of retrieval accuracy and speed, this representation yields a compromise between the other two representations.
Due to the slow retrieval of the contour representation, we propose a new melodic representation, a sequence of pitch histograms. This representation segments the sung query into several regions based on the pauses between some sung notes. The histogram representation has the advantage of being a very short time series, typically with fewer than ten elements, but has the disadvantage that each element may align with multiple notes in the target theme. This complicates the alignment procedure, for the alignment matrix must now have three dimensions instead of two. A sample alignment is shown to the left. Both in terms of retrieval accuracy and speed, this representation yields a compromise between the other two representations.
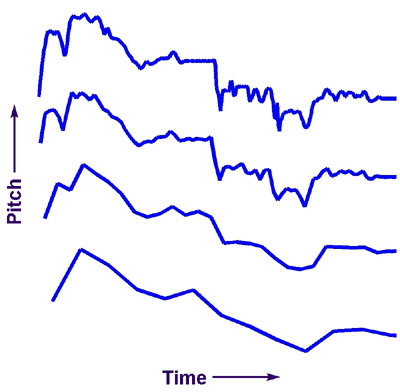 The comparison of the three representations demonstrated that the best performance can only be achieved with the slowest representation. However, the contour representation has an additional property that we will exploit in order to achieve both robust and fast retrieval: the contour representation can be easily down-sampled to any length, as shown in the figure to the right. As the pitch contour is down-sampled, it loses detail, but it also becomes faster to align. While a ‘short’ contour does not, by itself, provide for accurate retrieval, we can use it to prune the target database of themes that very different from the sung query. This implies that we can iteratively refine our search, and only perform the slowest alignment on a small fraction of the target database. Using this technique we can achieve about a 20-fold speed increase over the direct use of the contour representation, without degrading retrieval accuracy.
The comparison of the three representations demonstrated that the best performance can only be achieved with the slowest representation. However, the contour representation has an additional property that we will exploit in order to achieve both robust and fast retrieval: the contour representation can be easily down-sampled to any length, as shown in the figure to the right. As the pitch contour is down-sampled, it loses detail, but it also becomes faster to align. While a ‘short’ contour does not, by itself, provide for accurate retrieval, we can use it to prune the target database of themes that very different from the sung query. This implies that we can iteratively refine our search, and only perform the slowest alignment on a small fraction of the target database. Using this technique we can achieve about a 20-fold speed increase over the direct use of the contour representation, without degrading retrieval accuracy.
Finally, we propose the use of an adaptive alignment window to double the speed of the iterative retrieval system. All of the alignment methods described above employ an alignment window to speed computation. By using the alignment paths from previous iterations, we can construct a narrow alignment window and speed the alignment procedure by a factor of two. An example adaptive alignment window is shown in the figure below. The alignment window for the long contour is computed from the alignment path that was found for the short contour.

Conclusion
We compared three melodic representations and found that the often-used sequence of notes is not a robust representation for casually sung queries, although this representation does yield fast retrieval. Furthermore, we found that the best retrieval performance was achieved by the relatively slow contour representation. We then explored two methods of speeding the retrieval with this representation, and found that we could speed retrieval by a factor of 40 without degrading retrieval performance.
Portions of this work are described in:
Adams, N., Bartsch, M., Shifrin, J., and Wakefield, G., “Time Series Alignment for Music Information Retrieval,” Proc. Int. Conf. on Music Inf. Retrieval (ISMIR), Oct. 2004, Barcelona, Spain.
Adams, N., Marquez, D., and Wakefield, G., “Iterative Deepening for Melody Alignment and Retrieval,” Proc. Int. Conf. on Music Inf. Retrieval (ISMIR), Sept. 2005, London, UK.