We developed two hands-free music information retrieval (MIR) systems
that enable a user to retrieve and play back a musical piece
by saying its title or the artist's name.
Although various interfaces for MIR have been proposed,
speech-recognition interfaces suitable for retrieving musical pieces
have not been studied.
Our MIR-based jukebox systems employ
two different speech-recognition interfaces for MIR,
speech completion and
speech spotter,
which exploit intentionally controlled nonverbal speech information
in original ways.
The first is
a music retrieval system with the speech-completion interface
that is suitable for music stores and car-driving situations.
When a user only remembers part of the name of a musical piece or an artist
and utters only a remembered fragment,
the system helps the user recall and enter the name
by completing the fragment.
The second is
a background-music playback system with the speech-spotter interface
that can enrich human-human conversation.
When a user is talking to another person,
the system allows the user to enter
voice commands for music playback control
by spotting a special voice-command utterance
in face-to-face or telephone conversations.
Experimental results from use of these systems
have demonstrated the effectiveness of
the speech-completion and speech-spotter interfaces.


-
Demonstration of Music-Retrieval System with the Speech-Completion Interface
In this video,
a user can retrieve
a musical piece or a list of musical pieces by an artist
even if the user can remember only part of the name of the piece or artist.
[Details]:
The speech-completion function is invoked
by an intentional filled pause
(a vowel-lengthening hesitation like "er...").
A user who does not remember the last part of a name
can invoke this completion
by uttering the first part
while intentionally lengthening its last syllable (making a filled pause).
Here, the user can insert a filled pause at
an arbitrary position (even within a word).
The user then gets a numbered list of completion candidates
whose beginnings acoustically resemble the uttered fragment.
On the other hand,
a user who does not remember the first part of a name
can invoke this completion
by uttering the last part
after intentionally lengthening the last syllable of
a predefined special keyword --- called the wildcard keyword
(in the current implementation,
we use the Japanese wildcard "nantoka" (in English, "something")).
The user then gets a numbered list of completion candidates
whose endings acoustically resemble the uttered last part.
Completion candidates are
generated by replacing the wildcard keyword (filling in the first part)
as if a wildcard search was done.
 Demonstration of Music-Retrieval System with the Speech-Completion Interface
(11,506,124 bytes, 1 min 3 sec, MPEG-1 file)
(Short excerpt version:
3,058,384 bytes, 16 sec, MPEG-1 file)
Demonstration of Music-Retrieval System with the Speech-Completion Interface
(11,506,124 bytes, 1 min 3 sec, MPEG-1 file)
(Short excerpt version:
3,058,384 bytes, 16 sec, MPEG-1 file)
[Video transcript]
Forward Speech Completion: Music retrieval by uttering part of artist's name
Michael- (Michael, uh...)
(*)
A pop-up window containing completion candidates appears.
Jackson
(*)
A pop-up window containing a list of musical pieces appears.
No. 1
(*)
The first song is highlighted and played back.
Forward Speech Completion: Music retrieval by uttering part of musical-piece title
The Way- (The Way, er...)
(*)
A pop-up window containing completion candidates appears.
No. 1
(*)
The song of the selected title is played back.
Backward Speech Completion: Music retrieval by uttering part of artist's name
Something- (wildcard keyword)
(*)
A pop-up window with colorful flying decorations appears.
Jackson
(*)
A pop-up window containing completion candidates appears.
No. 1
(*)
A pop-up window containing a list of musical pieces appears.
No. 3
(*)
The third song is highlighted and played back.
This demonstration featured RWC-MDB-G-2001 No.10, 24, 26 from the
RWC Music Database (Music Genre).
-
Demonstration of Music Playback System with the Speech-Spotter Interface
In this video,
a user can listen to background music
by uttering the name of a musical piece or artist
while talking to another person.
The video shows that users can share music playback on the telephone
as if they were talking in the same room with background music.
[Details]:
The speech-spotter interface
regards a user utterance as a command utterance
only when
it is intentionally uttered with a high pitch just after a filled pause
such as "er..." or "uh...".
In other words,
a computer system accepts
this specially designed unnatural utterance only and
ignores other normal utterances in human-human conversation.
We dare to use the unnaturalness of nonverbal speech information ---
in this case
an intentional filled pause and a subsequent high-pitch utterance ---
because this combination is not normally uttered
in human-human conversation
but nevertheless can be easily uttered.
Demonstration of Music Playback System with the Speech-Spotter Interface
(12,793,620 bytes, 1 min 10 sec, MPEG-1 file)
(Short excerpt version:
3,760,232 bytes, 20 sec, MPEG-1 file)
[Video transcript]
B calls A on the telephone.
- A:
Yes...
- B:
Hello?
- A:
Uh..., what's up?
- B:
Thanks for all your help last time.
- A:
No problem. How have you been since?
- B:
Whew! I've been super busy writing that paper... I'm beat.
(Several minutes later)
- A:
Uh..., that reminds me,
the song called "Fly Away" that we heard at that place, wasn't that good?
- B:
Oh, what song was that?
- A:
Shall we try listening to it?
- B:
What? We can hear it now?
- A:
Sure. This is a phone with a music-playback system.
We can listen to that song like this...
Er..., " Fly Away"!
(*)
The system plays the song of that name on both of their handsets.
- B:
Wow, amazing! You can listen to a song by just saying its name!
Um..., this is a good song.
- A:
That's right!
(**)
In this caption, underlining indicates
that the pitch of the underlined words is intentionally raised.
This demonstration featured RWC-MDB-P-2001 No.28 from the
RWC Music Database (Popular Music).
|
Forward Speech Completion |
A user who does not remember the last
part of a name can invoke this completion by uttering
the first part while intentionally lengthening its last syllable
(making a filled pause).
[Entering the phrase "maikeru jakuson" ("Michael
Jackson") when its last part ("jakuson") is uncertain.]
-
Uttering "maikeru--."
-
A pop-up window containing completion candidates appears.
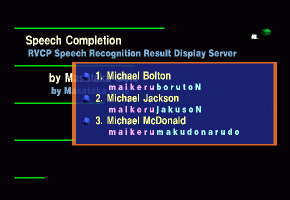
-
Uttering "No. 2."
-
The second candidate is highlighted and bounces.

-
The selected candidate "maikeru jakuson" is determined as the recognition result.

|
Backward Speech Completion |
A user who does not remember the first
part of a name can invoke this completion
by uttering the last part
after intentionally lengthening the last syllable of
a predefined special keyword --- called the wildcard keyword.
[Entering the phrase "maikeru jakuson" ("Michael Jackson")
when its first part ("maikeru") is uncertain.]
-
Uttering "nantoka--."
(wildcard keyword)
-
A pop-up window with colorful flying decorations appears.
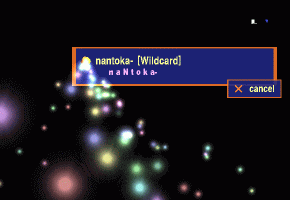
-
Uttering "jakuson."
-
A window containing completion candidates appears.
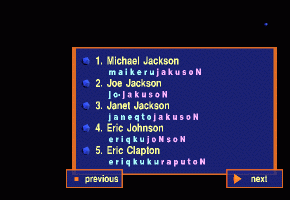
-
Uttering "No. 1."
-
The first candidate "maikeru jakuson" is determined as the recognition result.
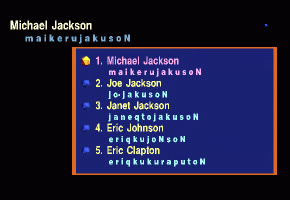
After the artist's name is identified
by either the forward or backward speech completion,
the system shows
a numbered list of titles for the specified artist in a music database,
and a user can select an appropriate title
by uttering either the title or its number.
When the musical piece is identified,
the system plays back its sound file.
[Playing back a musical piece of the artist "maikeru jakuson"
("Michael Jackson")
whose name is determined by the speech-completion interface.]
-
Continued from the above figures.
-
A pop-up window containing a list of musical pieces appears.
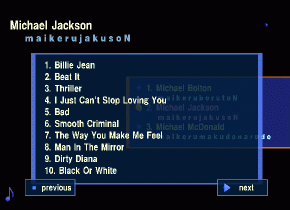
-
Uttering "No. 1."
-
The first musical piece is highlighted and played back.

The purpose of this research is
to build a music-retrieval system with
a speech-recognition interface that
facilitates both identification of a musical piece and
music playback in everyday life.
We think a speech-recognition interface
is well-suited to music information retrieval (MIR),
especially retrieval of a musical piece
by entering its title or the artist's name.
At home or in a car, for example,
an MIR-based jukebox system with a speech-recognition interface
would allow users to change background music
just by saying the name of a musical piece or an artist.
At music-listening stations in music stores or on karaoke machines,
a speech-recognition interface could also
help users find musical pieces they have been looking for
without using any input device other than a microphone.
Most previous MIR research, however, has not explored
how speech recognition can be used for retrieving music information,
although various MIR interfaces using text, symbols, MIDI, or audio signals
have been proposed.
To retrieve a musical piece,
a typical approach is to use a text query
related to bibliographic information.
This approach requires the use of hand-operated input devices,
such as a computer keyboard, mouse, or stylus pen.
Another approach is to use a melody-related query
given through symbols, MIDI, or audio signals.
In particular,
music retrieval through a sung melody is called query by humming (QBH),
and this approach is considered promising
because it requires only a microphone and can easily be used by a novice.
However, even though this approach uses a microphone,
speech recognition of the names of musical pieces and artists
has not been considered.
Against the above background,
we developed two original speech-recognition interfaces,
speech completion and
speech spotter,
which are suitable for MIR.
The speech-completion function requires
real-time detection of a filled pause and
the generation of a list of completion candidates:
- Real-time detection of a filled pause
To meet the first requirement,
we use our robust filled-pause detection method.
This is a language-independent bottom-up method
that can detect a lengthened vowel in any word
through a sophisticated signal-processing technique.
It determines the beginning and end of each filled pause
by finding two acoustical features of filled pauses ---
small F0 (voice pitch) transitions and
small spectral envelope deformations.
- Generation of a list of completion candidates
To meet the second requirement,
we extended a typical HMM-based speech recognizer
to provide a list of completion candidates
whenever a filled pause was detected (even within a word).
Because single phonemes cannot be recognized accurately enough,
up-to-date speech recognizers
do not determine a word's phoneme sequence phoneme by phoneme.
Instead, they choose the maximum likelihood (ML) hypothesis
while pursuing multiple hypotheses on a vocabulary tree
where all vocabulary words are stored.
When the beginning of a filled pause is detected,
the recognizer determines which completion method is to be invoked
(forward or backward).
The forward speech completion is achieved by deriving from the vocabulary tree
completion candidates that share the prefix corresponding to
each incomplete plausible word hypothesis for the uttered fragment.
The backward speech completion is achieved
by recognizing a last-part fragment uttered after the wildcard keyword;
since we cannot register such a word fragment as a vocabulary word in advance,
every syllable in the middle of all the vocabulary words
is dynamically searched just after the wildcard keyword.
The speech-spotter function requires
real-time detection of a filled pause,
determination of the endpoints of an utterance,
and
judgment as to whether the pitch of an utterance is
intentionally raised:
- Real-time detection of a filled pause
We use the same filled-pause detection method
as in the speech-completion function.
- Determination of the endpoints of an utterance
The end of each utterance is automatically determined
by using an intermediate speech-recognition result,
which is the ML hypothesis in
the HMM-based speech recognizer.
It monitors the ML hypothesis at every frame
and
stops decoding (determines the end of the utterance)
when the ML hypothesis reaches a silent pause or
when there is no possibility of other recognition results.
- Judgment as to whether the pitch of an utterance is intentionally raised
Because the pitch range of voices differs among individuals,
it is difficult to judge
whether the pitch of an utterance is intentionally shifted (raised).
We therefore introduced a unique pitch reference for each speaker,
called the base fundamental frequency (base F0),
which represents the pitch of the speaker's natural voice.
We use an original method of estimating the base F0
by averaging the voice pitch during a filled pause:
we found that the pitch during filled pauses is stable and
is close to the pitch of the natural voice.
After estimating the base F0,
we can deal with the pitch value relative to the base F0,
which compensates for a wide variety of voice pitch ranges.
If the relative pitch value of an utterance,
which is calculated by subtracting the base F0
from the pitch averaged over the utterance,
is higher than a threshold,
it is judged to be intentionally shifted.
The main contribution of this research
is to propose two novel speech-recognition interfaces suitable for MIR,
speech completion and
speech spotter,
and demonstrate their usefulness
in two different music jukebox systems.
The music retrieval system with the speech-completion interface
enables a user to listen to a musical piece
even if part of its name cannot be recalled.
The background-music playback system with the speech-spotter interface
enables users to share music playback on the telephone
as if they were talking in the same room with background music.
As far as we know, this is the first system
that people can use to obtain speech-based music information assistance
in the midst of a telephone conversation.
We believe that
practical speech-recognition interfaces for MIR
cannot be achieved by simply applying
the current automatic speech recognition to MIR:
retrieval of musical pieces
just by uttering entire titles or artist names is not sufficient.
Our two interfaces can be considered an important first step
toward building the ultimate speech-capable MIR interface.
It will become more and more important to explore
various speech-recognition interfaces for MIR
as well as other traditional MIR interfaces.
This research
utilized the
RWC Music Database "RWC-MDB-P-2001" (Popular Music)
and "RWC-MDB-G-2001" (Music Genre).
For more information, go to http://staff.aist.go.jp/m.goto/MIR/speech_if.html
.
[ Lay Language Paper Index | Press Room ]
