
John R. Iversen, Ph.D. - iversen@nsi.edu
Aniruddh D. Patel, Ph.D. - apatel@nsi.edu
The Neurosciences Institute
10640 John Jay Hopkins Dr
San Diego, CA 92121
Kengo Ohgushi, Ph.D. - ohgushi-19.38@r7.dion.ne.jp
Kyoto City University of Arts
Kyoto, Japan
Popular version of paper 3aPP5
Presented Thursday morning, November 30th, 2006
4th ASA/ASJ Joint Meeting, Honolulu, HI
When we listen to the ticking of a clock, we often hear "tick-tock," even if the sounds the clock makes are identical (try this with your wristwatch). The reason for this is that we naturally group sounds together into larger rhythmic units. Grouping is an essential component of speech and music perception, affecting, for example, how we break a continuous stream of sound into words and phrases. More than a century ago, scientists described several rules that govern how we group sounds. Since these rules hold for listeners across a number of different Western cultures, they have come to be thought of as universal, innate aspects of auditory perception. We find, however, that listeners from a Western and an Eastern culture (America and Japan) group simple tone patterns in different ways. That is, they perceive different rhythms in identical sequences of sound. This difference appears to be closely related to the rhythms of each culture's predominant language, English and Japanese, suggesting that the mother tongue affects how we perceive non-linguistic sound at a very basic level.
Researchers have long investigated rhythmic grouping using simple tone sequences.1,2 For example, listeners are presented with tones that alternate in loudness (...loud-soft-loud-soft...) or duration (...long-short-long-short...) and are asked to indicate their perceived grouping. Two principles established a century ago, and confirmed in numerous studies since, are widely accepted:
1) A louder sound tends to mark the beginning of a group.
2) A lengthened sound tends to mark the end of a group.
These principles have come to be viewed as universal laws of perception, underlying the rhythms of both speech and music.3,4 However, the cross-cultural data have come from a limited range of cultures (American, Dutch, and French). In our experiment, native speakers of Japanese and native speakers of American English listened to sequences of tones. The tones alternated in loudness ("Amplitude" sequences) or in duration ("Duration" sequences), as shown in Figure 1. Listeners told the experimenters how they perceived the grouping. (Sound Examples of the stimuli are provided, so you may try the experiment yourself.) Japanese and English speakers agreed with principle 1): both reported that they heard repeating loud-soft groups. However, the listeners showed a sharp difference when it came to principle 2). While English speakers perceived the "universal" short-long grouping, many Japanese listeners strongly perceived the opposite pattern, i.e., repeating long-short groups.5 Since this finding was surprising and contradicted a "law" of perception, we have replicated it with listeners from different parts of Japan. The finding is robust and calls for an explanation. Why would native English and Japanese speakers differ in this way?
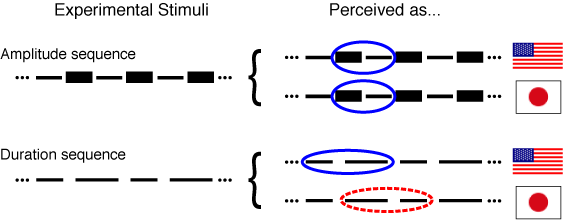
Figure 1. A cultural difference in rhythm perception.
Left side: Schematic of sound sequences used in the perception experiment. These sequences consist of tones alternating in loudness ("Amplitude sequence," top) ,or duration ("Duration sequence," bottom). In the Amplitude sequence, thin bars correspond to softer sounds and thick bars correspond to louder sounds. In the Duration sequence, short bars correspond to briefer sounds and long bars correspond to longer sounds. The dots before and after the sequences indicate that only an excerpt of a longer sequence of alternating tones is shown.
Right side: Perceived rhythmic grouping by American and Japanese listeners, indicated by ovals. Blue ovals (solid line) indicate preferences that follow "universal" principles of perception. Japanese and Americans perceived the Duration sequences differently. In these sequences, American listeners consistently perceived a repeating short-long pattern. There was variability among Japanese listeners in their perceived grouping, but the most commonly reported pattern was long-short (red oval, dashed line).
Sound Examples
Assuming that the perceptual difference we observed is not innate, what aspect of auditory experience might be responsible for this difference? Two obvious candidates are music and speech, since these sound patterns surround humans throughout their life. Both patterns present the ear with sequences of sound that must be broken into smaller coherent chunks, such as phrases in music, or phrases and words in speech. Might the temporal rhythm of these chunks differ for music or speech in the two cultures? That is, might short-long patterns be more common in American music or speech, and long-short be more common in Japanese music or speech? If so, then learning these patterns might influence auditory segmentation generally, and explain the differences we observe.
Focusing on music, one relevant issue concerns the rhythm of how musical phrases begin in the two cultures. For example, if most phrases in American music start with a short-long pattern (e.g., a pick-up note), and most phrases in Japanese music start with a long-short pattern, then listeners might learn to use these patterns as segmentation cues. To test this idea, we examined phrases in American and Japanese children's songs (because we believe these perceptual biases are probably laid down early in life). We examined 50 songs per culture, and for each phrase we computed the duration ratio of the first to the second note and then counted how often phrases started with a short-long pattern vs. other possible patterns (e.g. long-short, or equal duration). The results are shown in Figure 2.
American songs show no bias to start phrases with a short-long pattern. Interestingly, Japanese songs show a bias to start phrases with a long-short pattern, consistent with our perceptual findings. However, the musical data alone cannot explain the cultural differences we observe, because this data cannot explain the short-long grouping bias of American listeners.
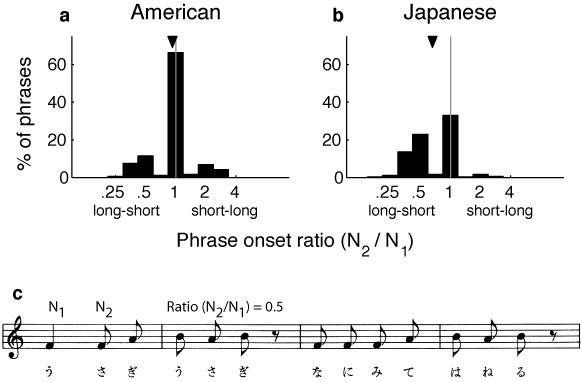
Figure 2: Distribution of phrase-onset duration ratios for (a) American and (b) Japanese childrens songs. Averages indicated by arrowheads. (c) Example of calculation of phrase-onset rhythm.
One basic difference between English and Japanese concerns word order.6 For example, in English, short grammatical (or "function") words such as "the," "a," "to," etc., come at the beginning of phrases and combine with longer meaningful (or content) words (such as a noun or verb). Function words are typically "reduced," having short duration and low stress. This creates frequent linguistic chunks that start with a short element and end with a long one, such as "the dog," "to eat," "a big desk," etc. This fact about English has long been exploited by poets in creating the English languages most common verse form, iambic pentameter.
Japanese, in contrast, places function words at the ends of phrases. Common function words in Japanese include "case markers," short sounds which can indicate whether a noun is a subject, direct object, indirect object, etc. For example, in the sentence "John-san-ga Mari-san-ni hon-wo agemashita," ("John gave a book to Mari") the suffixes "ga," "ni," and "wo" are case markers indicating that John is the subject, Mari is the indirect object and "hon"(book) is the direct object. Placing function words at the ends of phrases creates frequent chunks that start with a long element and end with a short one, which is just the opposite of the rhythm of short phrases in English.7
Apart from short phrases, the other short meaningful chunks in language are words. Because our perception experiment focused on 2-element groups, we examined the temporal shape of common disyllabic words in English and Japanese. English disyllabic words tend to be stressed on the first syllable (e.g. WO-man, PER-son)8, which might lead one to think that they would have a long-short rhythmic pattern of syllable duration. To test this, we had speakers of English read the 50 most common disyllabic words in the language (embedded within phrases), and measured the relative duration of the two syllables. Surprisingly, common words with stress on the first syllable did not have a strong bias toward a long-short duration pattern. In contrast, common words with stress on the second syllable, such as "a-BOUT," "be-CAUSE," and "be-FORE," had a very strong short-long duration pattern. Thus the average duration pattern for common 2-syllable words in English was short-long (Figure 3). This means that a short-long rhythm pattern is reflected at both the level of small phrases and common disyllabic words in English.
We also had Japanese speakers read the 50 most common disyllabic words in their language. In contrast to English, the average duration pattern for such words was long-short (Figure 3). Thus once again, linguistic rhythm mirrored the results of the perception experiment.
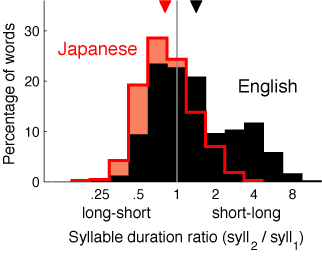
Figure 3: Distribution of syllable duration ratios for common two-syllable words in Japanese (red) and English (black). Averages indicated by arrowheads. Both averages are significantly different from zero.
We have found that the perception of rhythmic grouping, long thought to follow universal principles, actually varies by culture. Our explanation for this difference is based on the rhythms of speech. Specifically, we suspect that learning the typical rhythmic shape of phrases and words in the native language has a deep effect on rhythm perception in general. If our idea is correct, then rhythmic grouping preferences should be predictable from the temporal structure of small linguistic chunks (phrases and words) in a language.
Our findings highlight the need for cross-cultural work when it comes to testing general principles of auditory perception. Much of the original work on rhythmic grouping of tones was done with speakers of Western European languages (e.g., English, Dutch and French). While these languages do indeed have important differences, they all follow the pattern of putting short function words at the onset of small linguistic phrases, which may account for the similarity of perceptual grouping in these cultures. A more global perspective reveals that languages with phrase-final short function words are widespread, but exist largely outside of Europe, e.g., in India and East Asia.9 We predict that native speakers of these language will group tones of alternating duration like Japanese listeners do (long-short).
An important future direction for this work concerns the development of rhythmic grouping preferences in childhood. Do infants have an innate bias for a particular grouping pattern (e.g., short-long), which is then modified by experience? Or are they rhythmic blank slates? More generally, how and when do grouping preferences develop, and what impact do they have on the ability to acquire a second language with a rhythmic structure different from the native language?
We thank Mark Baker, Jennifer Burton, Bruno Repp, Jenny Saffran, Ben Stein, and Katie Yoshida for helpful input. This work was supported by Neurosciences Research Foundation as part of its program on music and the brain at The Neurosciences Institute, where JRI is the Karp Foundation Fellow and ADP is the Esther J. Burnham Fellow. This work was additionally supported by Grant No. 14101001 from the Japan Society for the Promotion of Science.
1. Bolton, T. (1894). Rhythm. The Am. J. of Psychol. 6, 145-238.
2. Woodrow, H.A. (1909). A quantitative study of rhythm: The effect of variations in intensity, rate and duration. Archives of Psychology 14, 1-66.
3. Hayes, B. (1995). The rhythmic basis of the foot inventory. In: B. Hayes (Ed.), Metrical stress theory: Principle and case studies (pp. 79-85). Chicago: The University of Chicago Press.
4. Hay, J.S.F. & Diehl, R.L. (in press). Perception of rhythmic grouping: Testing the Iambic/Trochaic law. Perception and Psychophysics.
5. This confirmed earlier unpublished research by Kusumoto, K., & Moreton, E. (1997). Native language determines parsing of nonlinguistic rhythmic stimuli. Poster presented at the 134th meeting of the Acoustical Society of America, San Diego, CA December 1997.
6. Baker, M. (2001). The Atoms of Language. New York: Basic Books.
7. Morgan, J.L., Meier, R.P. & Newport, E.L. (1987). Structural packaging in the input to language learning: Contributions of prosodic and morphological marking of phrases in the acquisition of language. Cognitive Psychology, 19, 498-550.
8. Cutler, A. & Carter D.M. (1987). The predominance of strong initial syllables in the English vocabulary. Computer Speech and Language, 2, 133-142.
9. Haspelmath, M., Dryer, M.W., Gil, D., & Comrie, B. (2005). The World Atlas of Language Structures. New York: Oxford Univ. Press.