
2aBAa3 – Towards a better understanding of myopia with high-frequency ultrasound
Jonathan Mamou – jmamou@riversideresearch.org
Daniel Rohrbach
Lizzi Center for Biomedical Engineering, Riverside Research, New York, NY, USA
Sally A. McFadden – sally.mcfadden@newcastle.edu.au
Vision Sciences, Hunter Medical Research Institute and School of Psychology, Faculty of Science, University of Newcastle, NSW, Australia
Quan V. Hoang – donny.hoang@snec.com.sg
Department of Ophthalmology, Columbia University Medical Center, New York, NY USA
Singapore Eye Research Institute, Singapore National Eye Centre, DUKE-NUS, Singapore
Myopia, or near-sightedness, affects up to 2.3 billion people and has a high prevalence. Although minimal levels of myopia are considered a minor inconvenience, high myopia is associated with sight-threatening pathology in 70% of patients and is highly prevalent in East Asians. By 2050, an estimated one billion people will have high myopia. High-myopia patients are prone to developing “pathologic myopia”, in which a high likelihood of permanent vision loss exists. Myopia is caused by an excessive eye length for the focusing power of the eye. Pathologic myopia occurs at extreme levels of lifelong, progressive eye elongation and subsequent thinning of the eye wall (sclera) and development of localized outpouchings (staphyloma). A breakdown in the structural integrity of the eye wall likely underlies myopic progression and precedes irreversible vision loss.
The guinea pig is a well-established animal model of myopia. With imposed blurring of the animals vision early in life, guinea pigs experience excessive eye elongation and develop high myopia within a week, which leads to pathologic myopia within 6 weeks. Therefore, we investigated two, fine-resolution ultrasound-based approaches to better understand and quantify the microstructural changes occurring in the posterior sclera associated with high-myopia development. The first approach termed quantitative-ultrasound (QUS) was applied to intact ex-vivo eyeballs of myopic and control guinea-pig eyes using an 80-MHz ultrasound transducer (Figure 1).

QUS yields parameters associated with the microstructure of tissue and therefore is hypothesized to provide contrast between control and myopic tissues. The second approach used a scanning-acoustic-microscopy (SAM) system operating at 250 MHz to form two-dimensional maps of acoustic properties of thin sections of the sclera with 7-μm resolution (Figure 2).

Like QUS, SAM maps provide striking contrast in the mechanical properties of control and myopic tissues at fine resolution. Initial results indicated that QUS- and SAM-sensed properties are altered in myopia and that QUS and SAM can provide new contrast mechanisms to quantify the progression and severity of the disease as well as to determine what regions of the sclera are most affected. Ultimately, these methods will provide novel knowledge about the microstructure of the myopic sclera that can improve monitoring and managing high myopia patients.
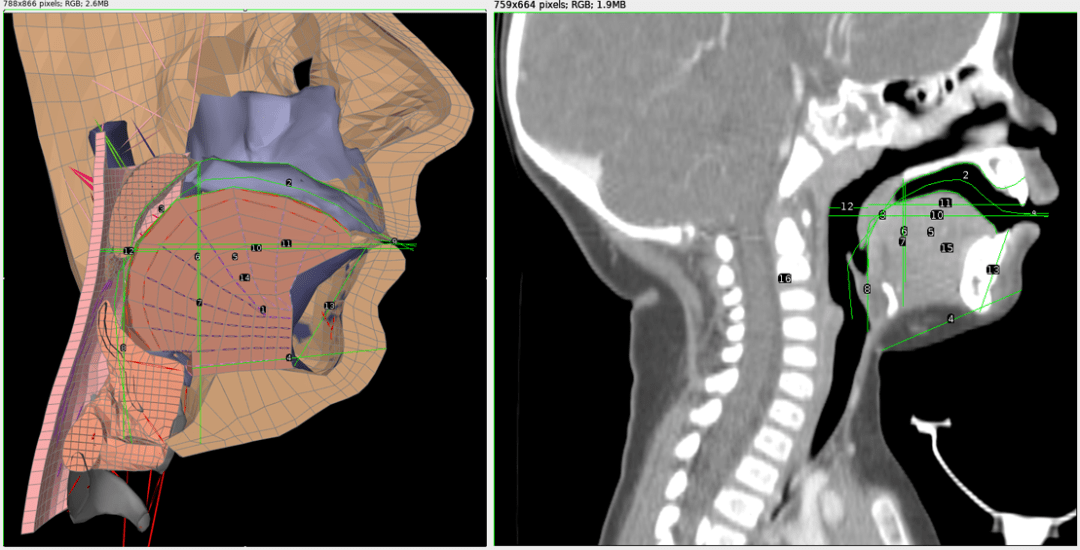 Figure 1: Left: A cross-section of the Frank model of an adult vocal tract with measurement lines. Right: A cross-sectional CT scan image of an 11 month old infant with measurement lines. The relative proportions of each vocal tract were compared to generate the infant model.
Figure 1: Left: A cross-section of the Frank model of an adult vocal tract with measurement lines. Right: A cross-sectional CT scan image of an 11 month old infant with measurement lines. The relative proportions of each vocal tract were compared to generate the infant model. Figure 2: A modified Frank vocal tract conforming to infant proportions.
Figure 2: A modified Frank vocal tract conforming to infant proportions.

 Figure 3: Reverb Time (T30) measurement for Lake Lethe
Figure 3: Reverb Time (T30) measurement for Lake Lethe Figure 4: Interior of the Wooden Bowl Room
Figure 4: Interior of the Wooden Bowl Room Figure 5: 1000ms waterfall analysis of Wooden Bowl Room showing a sustained resonance at 106.2 Hz
Figure 5: 1000ms waterfall analysis of Wooden Bowl Room showing a sustained resonance at 106.2 Hz Figure 6: Cleveland Avenue
Figure 6: Cleveland Avenue Figure 7: 1000ms waterfall analysis of Cleveland Avenue showing a sustained resonance at 118.6 Hz
Figure 7: 1000ms waterfall analysis of Cleveland Avenue showing a sustained resonance at 118.6 Hz Introduction
Introduction

 2A
2A 2B
2B
