
5aSC3 – Children’s perception of their own speech; A perceptual study of Polish /s, ʂ, ɕ/
Marzena Żygis – zygis@leibniz-zas.de
Leibniz Centre – General Linguistics & Humboldt University, Berlin, Germany
Marek Jaskuła – Marek.Jaskula@zut.edu.pl
Westpomeranian University of Technology, Szczecin, Poland
Laura L. Koenig – koenig@haskins.yale.edu
Adelphi University, Garden City, New York, United States; Haskins Laboratories; New Haven CT;
Popular version of paper 5aSC3, “Do children understand adults better or themselves? A perceptual study of Polish /s, ʂ, ɕ/”
Presented Friday morning, November 9, 2018, 8:30–11:30 AM, Upper Pavilion


Typically-developing children usually pronounce most sounds of their native language correctly by about 5 years of age, but for some “difficult” sounds the learning process may take longer. One set of difficult sounds is called the sibilants, an example of which is /s/. Polish has a complex three-way sibilant contrast (see Figure 1). One purpose of this study was to explore acquisitional patterns of this unusual sibilant set.
Further, most past studies assessed children’s accuracy in listening to adult speech. Here, we explored children’s perception of their own voices as well as that of an adult. It might be that children’s speech contain cues that adults do not notice, i.e. that they can hear distinctions in their own speech that adults do not.
We collected data from 75 monolingual Polish-speaking children, ages 35–95 months. The experiment had three parts. First, children named pictures displayed on a computer screen. Words only differed in the sibilant consonant, holding all other sounds constant (see Figure 1).
Figure 1: Word examples and attached audio (left, adult; right, child)
|
|
 |
|
 |
||
 |
Next, children listened to the words produced by an unknown adult and chose the picture corresponding to what they heard. Finally, they listened to their own productions, as recorded in the first part, and chose the corresponding picture. Our computer setup, “Linguistino”, allowed us to obtain the children’s response times via button-press, and also provided for recording their words in part 1 and playing them back, in randomized order, in part 3.
The results show three things. First, not surprisingly, children’s labeling is both more accurate and faster as they get older. The accuracy data, averaged over sounds, are shown in Figure 2.
Figure 2: Labeling accuracy
Further, some sibilants are harder to discriminate than others. Figure 3 shows that, across ages, children are fastest for the sound /ɕ/, and slowest for /ʂ/, for both adult and child productions. (The reaction times for /ʂ/ and /s/ were not significantly different, however).
Figure 2: Reaction time of choosing the sibilant /ɕ/, /s/ or /ʂ/ in function of age.
Finally, and not as expected, children’s labeling is significantly worse when they label their own productions vs. those of the adult. One might think that children have considerable experience listening to themselves, so that they would most accurately label their own speech, but this is not what we find.
These results lend insight into the specifics of acquiring Polish as a native language, and may also contribute to an understanding of sibilant perception more broadly. They also suggest that children’s internal representations of these speech sounds are not built around their own speech patterns.

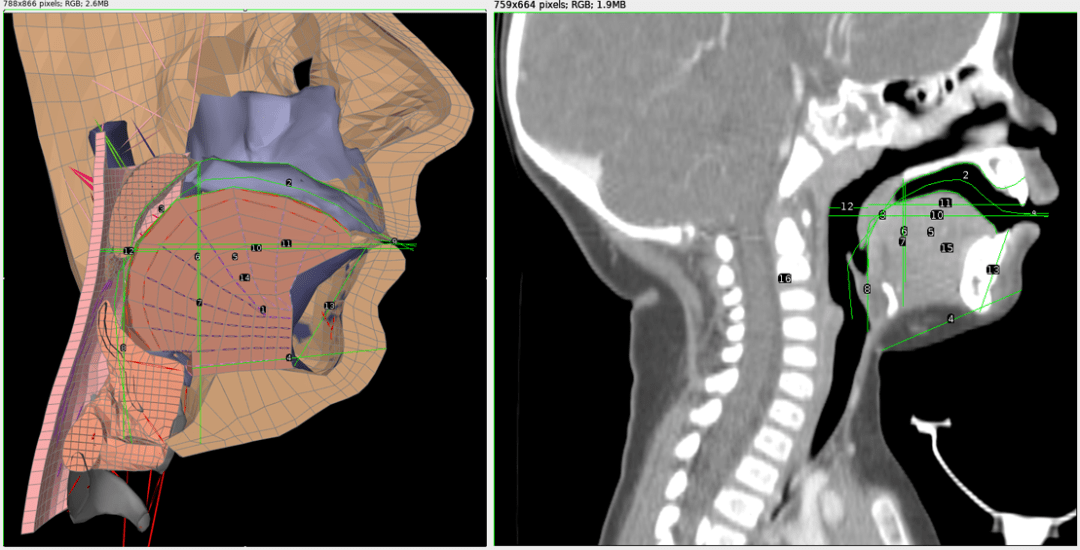 Figure 1: Left: A cross-section of the Frank model of an adult vocal tract with measurement lines. Right: A cross-sectional CT scan image of an 11 month old infant with measurement lines. The relative proportions of each vocal tract were compared to generate the infant model.
Figure 1: Left: A cross-section of the Frank model of an adult vocal tract with measurement lines. Right: A cross-sectional CT scan image of an 11 month old infant with measurement lines. The relative proportions of each vocal tract were compared to generate the infant model. Figure 2: A modified Frank vocal tract conforming to infant proportions.
Figure 2: A modified Frank vocal tract conforming to infant proportions.








