
2pABa1 – Snap chat: listening in on the peculiar acoustic patterns of snapping shrimp, the noisiest animals on the reef
Ashlee Lillis – ashlee@whoi.edu
T. Aran Mooney – amooney@whoi.edu
Marine Research Facility
Woods Hole Oceanographic Institution
266 Woods Hole Road
Woods Hole, MA 02543
Popular version of paper 2pABa1
Presented Tuesday afternoon, November 29, 2016
172nd ASA Meeting, Honolulu
Characteristic soundscape recorded on a coral reef in St. John, US Virgin Islands. The conspicuous crackle is produced by many tiny snapping shrimp.
Put your head underwater in almost any tropical or sub-tropical coastal area and you will hear a continuous, static-like noise filling the water. The source of this ubiquitous sizzling sound found in shallow-water marine environments around the world was long considered a mystery of the sea. It wasn’t until WWII investigations of this underwater sound, considered troublesome, that hidden colonies of a type of small shrimp were discovered as the cause of the pervasive crackling sounds (Johnson et al., 1947).
Individual snapping shrimp (Figure 1), sometimes referred to as pistol shrimp, measure smaller than a few centimeters, but produce one of the loudest of all sounds in nature using a specialized snapping claw. The high intensity sound is actually the result of a bubble popping when the claw is closed at incredibly high speed, creating not only the characteristic “snap” sound but also a flash of light and extremely high temperature, all in a fraction of a millisecond (Versluis et al., 2000). Because these shrimp form large, dense aggregations, living unseen within reefs and rocky habitats, the combination of individual snaps creates the consistent crackling sound familiar to mariners. Snapping is used by shrimp for defense and territorial interactions, but likely serves other unknown functions based on our recent studies.


Figure 1. Images of the species of snapping shrimp, Alpheus heterochaelis, we are using to test hypotheses in the lab. This is the dominant species of snapping shrimp found coastally in the Southeast United States, but there are hundreds of different species worldwide, easily identified by their relatively large snapping claw.
Since snapping shrimp produce the dominant sound in many marine regions, changes in their activity or population substantially alters ambient sound levels at a given location or time. This means that the behavior of snapping shrimp exerts an outsized influence on the sensory environment for a variety of marine animals, and has implications for the use of underwater sound by humans (e.g., harbor defense, submarine detection). Despite this fundamental contribution to the acoustic environment of temperate and coral reefs, relatively little is known about snapping shrimp sound patterns, and the underlying behaviors or environmental influences. So essentially, we ask the question: what is all the snapping about?
Figure 2 (missing). Photo showing an underwater acoustic recorder deployed in a coral reef setting. Recorders can be left to record sound samples at scheduled times (e.g. every 10 minutes) so that we can examine the long-term temporal trends in snapping shrimp acoustic activity on the reef.
Recent advances in underwater recording technology and interest in passive acoustic monitoring have aided our efforts to sample marine soundscapes more thoroughly (Figure 2), and we are discovering complex dynamics in snapping shrimp sound production. We collected long-term underwater recordings in several Caribbean coral reef systems and analyzed the snapping shrimp snap rates. Our soundscape data show that snap rates generally exhibit daily rhythms (Figure 3), but that these rhythms can vary over short spatial scales (e.g., opposite patterns between nearby reefs) and shift substantially over time (e.g., daytime versus nighttime snapping during different seasons). These acoustic patterns relate to environmental variables such as temperature, light, and dissolved oxygen, as well as individual shrimp behaviors themselves.
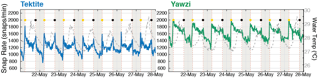
Figure 3. Time-series of snap rates detected on two nearby USVI coral reefs for a week-long recording period. Snapping shrimp were previously thought to consistently snap more during the night, but we found in this study location that shrimp were more active during the day, with strong dawn and dusk peaks at one of the sites. This pattern conflicts with what little is known about snapping behaviors and is motivating further studies of why they snap.
The relationships between environment, behaviors, and sound production by snapping shrimp are really only beginning to be explored. By listening in on coral reefs, our work is uncovering intriguing patterns that suggest a far more complex picture of the role of snapping shrimp in these ecosystems, as well as the role of snapping for the shrimp themselves. Learning more about the diverse habits and lifestyles of snapping shrimp species is critical to better predicting and understanding variation in this dominant sound source, and has far-reaching implications for marine ecosystems and human applications of underwater sound.
References
Johnson, M. W., F. Alton Everest, and Young, R. W. (1947). “The role of snapping shrimp (Crangon and Synalpheus) in the production of underwater noise in the sea,” Biol. Bull. 93, 122–138.
Versluis, M., Schmitz, B., von der Heydt, A., and Lohse, D. (2000). “How snapping shrimp snap: through cavitating bubbles,” Science, 289, 2114–2117. doi:10.1126/science.289.5487.2114













