
2aSP2 – Self-Driving Cars: Have You Considered Using Sound?
Keegan Yi Hang Sim – yhsim@connect.ust.hk
Yijia Chen
Yuxuan Wan
Kevin Chau
Department of Electronic and Computer Engineering
Hong Kong University of Science and Technology
Clear Water Bay
Hong Kong
Popular version of paper 2aSP2 Advanced automobile crash detection by acoustic methods
Presented Tuesday morning, December 03, 2019
178th Meeting, San Diego, CA
Read the article in Proceedings of Meetings on Acoustics
Introduction
Self-driving cars are currently a major interest for engineers around the globe. They incorporate more advanced versions of steering and acceleration control found in many of today’s cars. Cameras, radars, and lidars (light detection and ranging) are frequently used to detect obstacles and automatically brake to avoid collision. Air bags, which have been in use as early as 1951, soften the impact during an actual collision.
Vision Zero, an ongoing multinational effort, hopes that all car crashes will eventually be eliminated, and self-driving autonomous vehicles are likely to play a key role in achieving this. However, current technology is unlikely to be enough, as it does not works poorly in low light conditions. We believe that using sound, although it provides less which carries a unique information, is also important as it can be used in all scenarios and also likely performs much better.
Sound waves travel as fast as seventeen times faster in a car than at 1/3 of a kilometer per second in the air, which leads to much faster detection by using sound instead of acceleration, and clearly is not affected by light, air quality, and other factors. Previous research was able to use sound to detect collisions and sirens, but by the time a collision occurs, it is far too late. So instead we want to identify sounds that frequently occur before car crashes, such as tire skidding, honking, and sometimes screaming to figure out the direction they are coming from. Thus, we have designed a method to predict a car crash by detecting and isolating the sounds of tire skidding that might signal a possible crash.
Algorithm
The algorithm utilizes the discrete wavelet transform (DWT), which decomposes a sound wave into high- and low-frequency components in time all sorts of tiny waves each lasting for a short period in time. This can be done repeatedly, yielding a series of components of various frequencies. Using wavelets is significantly faster and gives much more accurate and precise results representation of transient events associated with car crashes than elementary techniques such as the Fourier Transform, which transforms a sound into its frequency steady oscillation components. Previous methods to detect car crashes examined the highest frequency components, but tire skidding only contains lower frequency components, whereas a collision contains almost all frequencies.
One can hear in the original audio of a car crash the three distinct sections: honking, tire skidding, and the collision.
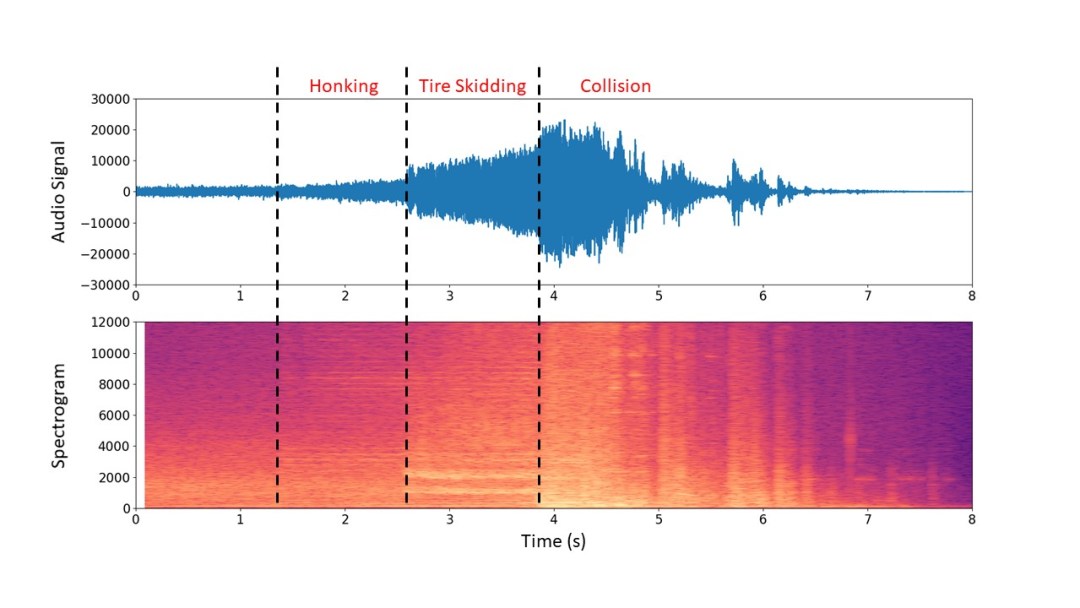
The top diagram shows the audio displayed as a waveform, plotted against time. The bottom shows a spectrogram of the audio, with frequency on the y-vertical axis and time on the horizontal x-axis, and the brightness of the color representing the magnitude of a particular frequency component. This was created using a variation of the Fourier Transform. One can observe the differences in appearance between honking, tire skidding, and collision, which suggests that mathematical methods should be able to detect and isolate these. We can also see that the collision occupies all frequencies while tire skidding occupies lower frequencies with two distinct sharp bands at around 2000Hz.
“OutCollision.wav , the isolated audio containing just that isolates the car crash”
Using our algorithm, we were able to create audio files containing just that isolate the honking, tire skidding, as well as the collision. One can hear that they doThey may not sound like normal honking, tire skidding or collisions, which is a byproduct of our algorithm. Fortunately, but this does not affect the ability to detect the tire skidding various events by a computer.
Conclusion
The algorithm performs well for detecting the honking and tire skidding, and is fast enough to be done in real time, before acceleration information can be processed which would be great for the raising the alert of a possible crash, and for activating the hazard lights and seatbelt pre-tensioners. The use of sound in cars is a big step forward for the analysis prevention of car crashes, as well as improving autonomous and driverless vehicles and achieving Vision Zero, by providing a car with more timely and valuable information about its surroundings.




 Figure 1: Fabricated prototype of origami folded frequency selective surface made of a folded plastic sheet and copper prints, ready to be tested in an anechoic chamber – a room padded with radio-wave-absorbing foam pyramids.
Figure 1: Fabricated prototype of origami folded frequency selective surface made of a folded plastic sheet and copper prints, ready to be tested in an anechoic chamber – a room padded with radio-wave-absorbing foam pyramids. Introduction
Introduction


