Michael Fay – mfay.gracenote@gmail.com GraceNote Design Studio 7046 Temple Terrace St. San Diego, CA 92119
Presented Tuesday afternoon, December 3, 2019 178th ASA Meeting, San Diego, CA
The T60 Slope Ratio thesis defines specific reverberation time vs. frequency goals for modern architectural acoustic environments. It is offered to advance and define a room’s acoustic design goals, and provide a simple numeric scoring scale, and adjunct grade, from which acoustical design specifications can be initiated and/or evaluated. The acronym for reverberation time is T60.
The thesis outlines a proposed standard that condenses six octaves (63 Hz – 2 kHz) of reverberant decay-time data into a single numeric score for grading indoor performance, worship and entertainment facilities. Specifically, it’s a defining metric for scoring and grading the relationship (i.e. ratio) between the longest and shortest of the six T60 values — be they measured or predicted.
Beranek’s classical Bass Ratio goals and calculations were developed to support the idea that acoustic instruments need a little extra support, via longer reverberation times, in the low-frequency range.
The modern T60 Slope Ratio goals and calculations advance the notion that those same low frequencies don’t require extra time, but rather need to be well contained. Longer low and very low-frequency (VLF) T60s are not needed or desirable when an extended-range sound reinforcement system is used.
Figure 2: Graphic Examples of 5 T60 Measurements
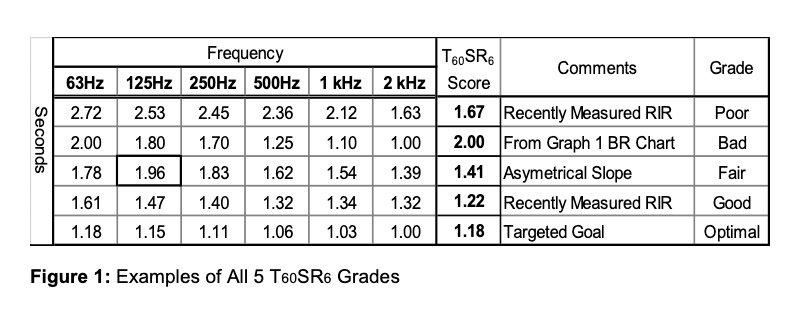
The T60 Slope Ratio is calculated by dividing the longest time by the shortest time, regardless of frequency. An optimal score has a ratio between 1.10 and 1.20.
The proposed scoring and grading scale is defined by six numeric scoring tiers from 1.00 to 1.70 and above, and five grading adjectives from Optimal to Bad. See Figure 3.
These modern applications would benefit from an optimal T60SR6 grade: ♣ Performing Arts Venues ♣ Contemporary Worship Facilities ♣ Venues with Electro-acoustical Enhancement Systems ♣ Large Rehearsal Rooms
Modern VLF testing standards and treatments are lacking: ♣ The ANSI and ISO standards organizations need to develop new guidelines and standards for testing VLF absorption products and integration options. ♣ Manufacturers should make new VLF treatment products an R&D priority.
More than one hundred years ago Walter Sabine, the father of classical architectural acoustics, was concerned that music halls would soak up too much of the low-frequency energy being produced by acoustic instruments, causing audiences to complain that the music lacked body. However today, most musical styles, venues, technology, and consumer tastes and expectations have advanced far beyond anything relevant to Sabine’s concern.
The Slope Ratio Postulate: Modern loudspeakers are designed and optimized to perform as flat, or nearly flat, audio output devices. Therefore, why aren’t acousticians designing a nearly-flat T60 response for rooms in which these loudspeakers operate?
Yuri Lysoivanov – yuri.lysoivanov@columbiacollege.edu Flashpoint Chicago, A Campus of Columbia College Hollywood 28 N. Clark St. #500 Chicago, IL 60602
Popular version of paper 2aAA8 Presented Tuesday morning, November 6, 2018 176th ASA Meeting, Victoria, Canada
The use of artificial reverberation in recorded music has been available since the late 1940s and is commonly credited to the ingenuity of Bill Putnam Sr. [1]. Following decades of technological achievement audio engineers are able to access an ever-growing variety of echo chambers, metal plates, springs, and digital emulations of an abundance of environments. A popular method in use today is the convolution reverb, a digital technique that uses controlled recordings of real spaces (called Impulse Responses or IRs) and applies them to every sample of a source sound, achieving an incredibly realistic simulation of that sound in the space.
Curiously, given their unique acoustic qualities, impulse responses of caves are generally underrepresented in the audio engineer’s toolkit. A browse through the responses in Altiverb, a popular high-end convolution reverb (figure 1), shows a small selection of caves relegated to the post-production (i.e. film sound) category ready to use for enterprising sound designers. This selection is far smaller than the availability of concert halls, churches, tombs, rooms and other acoustically critical spaces.
Figure 1: A search for “cave” in Altiverb reveals Howe’s Cavern in NY and two locations in Malta, in addition to several man-made structures.
One potential reason for the lack of availability of cave impulse responses could be the logistical difficulty in getting recording and measuring equipment into the caves. Another reason may be simply a lack of consumer interest, with so many fantastic impulse responses of man-made structures readily available.
For this paper, we sought to explore nature as architect and to demonstrate how incorporating the characteristics of these distinct structures can make a meaningful contribution to the audio engineer’s creative palate. With the aid of scientists from the National Parks Service, we chose a few locations for analysis within Mammoth Cave – the longest cave system in the world.
After capturing impulse responses, we analyzed the spaces to develop a set of useful applications for audio professionals. The Methodist Church was found to have a warm and pleasant sounding reverb to the ear (Figure 2), with a decay characteristic similar to a small concert hall. Lake Lethe, is an isolated, lengthy subterranean waterway, presents a smooth long decay (Figure 3) and is ideal for a multitude of echo applications. The Wooden Bowl Room (Figures 4 and 5) and Cleveland Avenue (Figures 6 and 7), were selected by our host scientist for having beautiful low, sustained resonances (which we found to be 106.2 Hz and 118.6 Hz, respectively) – suitable for applying depth and tension to a variety of sounds.
Figure 2: Reverb Time (T20) measurement for the Methodist Church.
Figure 3: Reverb Time (T30) measurement for Lake Lethe
Figure 4: Interior of the Wooden Bowl Room
Figure 5: 1000ms waterfall analysis of Wooden Bowl Room showing a sustained resonance at 106.2 Hz
These locations, carved over millions of years, provide opportunities for engineers to sculpt sounds that add an idiosyncratic character beyond the common reverbs available on the market. We hope that our work lays a foundation for further analysis of the characteristics of cave interiors and to a more individualized approach in using cave ambiences in music and sound design.
Figure 6: Cleveland Avenue
Figure 7: 1000ms waterfall analysis of Cleveland Avenue showing a sustained resonance at 118.6 Hz
[1] Weir, William. (2012, June 21). How Humans Conquered Echo. The Atlantic. Retrieved from https://www.theatlantic.com/
Zamir Ben-Hur – zami@post.bgu.ac.il Boaz Rafaely – br@bgu.ac.il Department of Electrical and Computer Engineering, Ben-Gurion University of the Negev, Beer-Sheva, 84105, Israel.
David Lou Alon – davidalon@fb.com Ravish Mehra – ravish.mehra@oculus.com Oculus & Facebook, 1 Hacker Way, Menlo Park, CA 94025, USA.
Popular version of paper 3aAA10, “Localization and externalization in binaural reproduction with sparse HRTF measurement grids”. Presented Wednesday morning, May 9, 2018, 11:40-11:55 AM, 175th ASA Meeting, Minneapolis.
High-quality spatial sound reproduction is important for many applications of virtual and augmented reality. Spatial audio gives the listener the sensation that sound arrives from the surrounding 3D space, leading to immersive virtual soundscapes. To create such a virtual sound scene with headphone listening, binaural reproduction technique is being used. A key component in binaural reproduction is the head-related transfer function (HRTF). An HRTF is a mathematical representation that describes how a listener’s head, ears, and torso affect the acoustic path originating from sound source’s direction into the ear canal [1]. HRTF set is typically measured for an individual in an anechoic chamber using an HRTF measurement system. Alternatively, a generic HRTF set is measured using a manikin. To achieve a realistic spatial audio experience, in terms of sound localization and externalization, high resolution personalized HRTF (P-HRTF) is necessary. Localization refers to the ability of presenting a sound at accurate locations in the 3D space. Externalization is the ability to perceive the virtual sound as coming from outside of the head, like real world environments.
Typical P-HRTF set is composed of several hundreds to thousands of source directions measured around a listener, using a procedure which requires expensive and specialized equipment and can take a long time to complete. This motivates the development of methods that require fewer spatial samples but still allow accurate reconstruction of the P-HRTF sets with high spatial resolution. Given only sparsely measured P-HRTF, it will be necessary to reconstruct directions that were not measured, which introduces interpolation error that may lead to poor spatial audio reproduction [2]. It is therefore important to better understand this interpolation error and its effect on spatial perception. If the error is too significant then a generic HRTF may be the preferred option over a sparse P-HRTF. Figure 1 presents an illustration of the question being answered in this study.
Figure 1. Illustration of the challenge of this paper.
Prior studies suggested to represent the HRTF in the spherical-harmonics (SH) domain. Using SH decomposition, it is possible to reconstruct high resolution P-HRTF from a low number of measurements [3,4]. When using SH representation, the reconstruction error can be caused by spatial aliasing and/or of SH series truncation [4,5,6]. Aliasing refer to loss of ability to represent high frequencies due to limited number of measurements. Truncation error refer to the order limit imposed on the SH representation which further limits the spatial resolution. With small number of measurements, both errors contribute to the overall reconstruction error.
In this study, the effect of sparse measurement grids on the reproduced binaural signal is perceptually evaluated through virtual localization and externalization tests under varying conditions.
Six adult subjects participated in the experiment. The experiment was performed with the Oculus Rift headset with a pair of floating earphones (see Fig. 2). These floating earphones enabled per-user headphone equalization for the study. A stimulus of 10 second band-passed filtered white noise (0.5-15 kHz) was played-back using real-time binaural reproduction system. The system allows reproduction of a virtual sound source in a given direction, using a specific HRTF set that was chosen according to the test condition. At each trial, the sound was played from a different direction, and the subject was instructed to point to this direction using a virtual laser pointer controlled by the subject’s head movement. Next, the participant was asked to report whether the stimulus was externalized or internalized.
Figure 2. The experiment setup, including a Rift headset and floating earphones.
We analyzed the localization results by means of angular errors. The angular errors were calculated as the difference between the perceptually localized position and the true target position. Figure 3 depicts the mean sound localization performance for different test conditions (Q, N), where Q is the number of measurements and N is the SH order. The figure shows averaged error across all directions (upper plot) and errors in azimuth and elevation (lower plots) separately. The externalization results were analyzed as average percentage of responses that the subjects marked as being externalized. Figure 4 shows the externalization results averaged across all directions and subjects.
The results demonstrate that high number of measurements leads to better localization and externalization performances, where most of the effect is in the elevation angles. Compared to the performance of a generic HRTF, P-HRTF with 121 measurements and SH order 10 achieves similar results. The results suggest that for achieving improved localization and externalization performance compare to a generic HRTF, at least 169 directional measurements are required.
Figure 3. Localization results of angular error (in degrees) for different conditions of (Q,N), where Q is the number of measurements and N is the SH order. Upper plot show the overall angular error, and lower plots show separate errors for azimuth and elevation.
Figure 4. Results of externalization performance.
References
[1] J. Blauert, “Spatial hearing: the psychophysics of human sound localization”. MIT press, 1997.
[2] P. Runkle, M. Blommer, and G. Wakefield, “A comparison of head related transfer function interpolation methods,” in Applications of Signal Processing to Audio and Acoustics, 1995., IEEE ASSP Workshop on. IEEE, 1995, pp. 88–91.
[3] M.J.Evans,J.A.Angus,andA.I.Tew,“Analyzing head-related transfer function measurements using surface spherical harmonics,” The Journal of the Acoustical Society of America, vol. 104, no. 4, pp. 2400–2411, 1998.
[4] G. D. Romigh, D. S. Brungart, R. M. Stern, and B. D. Simpson, “Efficient real spherical harmonic representation of head-related transfer functions,” IEEE Journal of Selected Topics in Signal Processing, vol. 9, no. 5, pp. 921–930, 2015.
[5] B. Rafaely, B. Weiss, and E. Bachmat, “Spatial aliasing in spherical microphone arrays,” IEEE Transactions on Signal Processing, vol. 55, no. 3, pp. 1003–1010, 2007.
[6] A. Avni, J. Ahrens, M. Geier, S. Spors, H. Wierstorf, and B. Rafaely, “Spatial perception of sound fields recorded by spherical microphone arrays with varying spatial resolution,” The Journal of the Acoustical Society of America, vol. 133, no. 5, pp. 2711–2721, 2013.
Oliver Buttler – oliver.buttler@uni-oldenburg.de Torben Wendt – torben.wendt@uni-oldenburg.de Steven van de Par – steven.van.de.par@uni-oldenburg.de Stephan D. Ewert – stephan.ewert@uni-oldenburg.de
Medical Physics and Acoustics and Cluster of Excellence Hearing4all, University Oldenburg Carl-von-Ossietzky-Straße 9-11 26129 Oldenburg, GERMANY
Popular version of paper 3aAA7, “Perceptually plausible room acoustics simulation including diffuse reflections” Presented Wednesday morning, May 9, 2018, 10:50-11:05 AM, Location: NICOLLET C 175th ASA Meeting, Minneapolis
Today’s audio technology allows us to create virtual environments where the listener feels immersed in the scene. This technology is currently used in entertainment, computer games, but also in research where the function of a hearing aid algorithm or the behavior of humans in complex and realistic situations is investigated. To create such immersive virtual environments, besides convincing computer graphics also convincing computer sound is of key importance. We can easily experience the richness of the acoustic world when we close our eyes. We can hear that the acoustic world allows us to perceive sounds in an omnidirectional way such that we can perceive a sound source from different directions or even around a corner, and we might even be able to hear whether we are in a concert hall or bathroom, based on the acoustics.
To create immersive and convincing acoustics in virtual reality applications, computationally efficient methods are required. While in the last decades, the development towards today’s astonishing real-time computer graphics was strongly driven by the first-person computer game genre, until recently, comparable techniques in computer sound received much less attention. One reason might be that the physics of sound propagation and acoustics is at least as complicated as that of light propagation and illumination, and computing power was mainly spent on computer graphics so far. Moreover, from early on, computer graphics focused on the creation of visually convincing results rather than on physics-based simulation which allowed for tremendous simplifications of the computations. Methods for simulating acoustics, however, often focused on physics-based to predict how a planned concert hall or classroom might sound like. These methods disregarded perceptual limitations of our hearing system that might allow for significant simplifications of the acoustic simulations.
Our perceptually plausible room acoustics simulator [RAZR, www.razrengine.com, 1] creates a computationally efficient acoustics simulation by drastic simplifications with respect to physical accuracy while still accomplishing a perceptually convincing result. To achieve this, RAZR approximates the geometry of real rooms by a simple, empty shoebox-shaped room and calculates the first sound reflections from walls as if they were mirrors creating image sources for a sound source in the room [2]. Later reflections that we perceive as reverb are treated in an even more simplified way and only the temporal decay of sound energy and the binaural distribution at our two ears is considered using a so-called feedback-delay-network [FDN, 3].
Although we demonstrated that a good perceptual agreement with real non-shoebox rooms is indeed achieved [1], the empty shoebox-room simplification might be too inaccurate for rooms which strongly diverge from this assumption, e.g., a staircase or a room with multiple interior objects. Here multiple reflections and scattering occur which we simulate in a perceptually convincing manner by temporal smearing of the simulated reflections. A single parameter was introduced to quantify deviations from an empty shoebox room and thus the amount of temporal smearing. We demonstrate that a perceptually convincing room acoustical simulation can be obtained for sounds like music and impulses similar to a hand clap. Given its tremendous simplifications, we believe that RAZR is optimally suited for real-time acoustics simulation even in mobile devices were virtual sounds could be embedded in augmented reality applications.
Figure 1. Examples for the simplification of different real room geometries to shoeboxes in RAZR. The red boxes indicate the shoebox approximation. The green box in panel c) indicates a second, coupled volume attached to the lower main volume. While the rooms in panel a) and b) might be well approximated with the empty shoebox, the rooms in panel c) and d) show more severe deviations which were accounted for by a single parameter estimating the deviation from the shoebox in percent and by applying the according temporal smearing to the reflections.
Figure 2. Perceptually rated differences between real room recordings (A: large aula, C: corridor, S: seminar room) and simulated rooms with a hand-clap-like sound source (pulse). Different perceptual attributes are shown in the panels. The error bars indicate inter-subject standard deviations. Depending on the attribute, ordinate scales range from “less pronounced” to “more pronounced” or semantically fitting descriptors. The different symbols show the amount of deviation from the empty shoebox assumption as percentage. It can be seen that with a deviation of 20% the critical attributes in the lower panel are rated near zero and thus show a good correspondence with the real room. The remaining overall difference is mainly caused by differences in tone color which can be easily addressed.
Figure 3. The virtual audio-visual environment lab at the University of Oldenburg features 86 loudspeakers and 8 subwoofers arranged in a full spherical setup to render 3-dimensional simulated sound fields. The foam wedges at the walls create an anechoic environment, so that the sound created by the loudspeakers is not affected by unwanted sound reflections at the walls.
Sound 1. Simulation of the large aula without the assumption of interior objects and multiple sound reflections on those objects. Although the sound is not distorted, an unnatural and crackling sound impression is obvious at the beginning.
Sound 2. Simulation of the large aula with the assumption of 20% of the empty space filled with objects. The sound is more natural and the crackling impression at the beginning is gone.
[1] T. Wendt, S. Van De Par, and S. D. Ewert, “A computationally-efficient and perceptually-plausible algorithm for binaural room impulse response simulation,” Journal of the Audio Engineering Society, 62(11):748–766, 2014.
[2] J. B. Allen and D. A. Berkley, “Image method for efficiently simulating small-room acoustics,” The Journal of the Acoustical Society of America, 65(4):943–950, 1979.
[3] J.-M. Jot and A. Chaigne, “Digital delay networks for designing artificial reverberators,” In 90th Audio Engineering Society Convention, Audio Engineering Society, 1991.
McKay Conant Hoover, Inc. 5655 Lindero Canyon Road, Suite 325 Westlake Village, CA 91362
Popular version of paper 2aAAa Presented Tuesday morning, May 08, 2018 175th ASA Meeting in Minneapolis, MN
Lobbies are a facility’s initial destination, the point of departure, the information center, and a security checkpoint.
It can be difficult to impose blanket acoustical criteria, because lobbies take an infinite number of forms, and must respond to building occupancy, fire safety, pedestrian flow, plus cultural tastes and architectural aesthetics.
The requirements can fluidly fluctuate throughout design, and the acoustics need to keep pace. The following can inform the acoustical design:
The primary functions include services for information, ticketing, and security, which necessitate speech intelligibility. This in turn suggests concentrating sound-absorptive treatments near ticketing and information booths where speech intelligibility is important, as well as providing shelter for task-oriented areas.
Great lobbies serve secondary functions, such as providing daylighting through large areas of glass, but glass is sound-reflective.
Some lobbies are very grand and can be several stories in height. This offers opportunities for ad hoc performances, especially for choral groups and chamber music. Sound-scattering treatments instead of sound-absorptive treatments help to provide a sense of “spaciousness.”
Noise, speech, or music generated in the lobby should not transmit to other spaces. Appropriate sound isolation can be achieved through careful placement of doors, vestibules, hallways, and partitions.
HVAC noise should be relatively quiet.
Figure 1 shows the grand lobby in a prominent performing arts center, with carefully-designed acoustical features:
Ceiling and corridors are highly diffusive, which scatter sound and soften individual sound reflections.
Balconies are large protruding elements that scatter sound.
Areas under the balconies and stairs offer noise shielding for patrons to comfortably purchase beverages and tickets, check coats, and engage with ushers.
Figure 1. An acoustically successful lobby
This lobby successfully hosts pre-function events such as small choral groups on the main stairwell, bustling cocktail hours, and many post-function events such as autographs, fund raising, and cabaret.
Figure 2 shows a five-story lobby in a large courthouse facility. The lobby is the main entrance for the facility, and connects the courthouse wing to the administrative wing via a series of stacked bridges.
Figure 2. Architectural rendering of the courthouse atrium
The design called for walls to be glass and brick, with a hard floor and wood ceiling. The resultant reverberation (time for sounds to decay to inaudibility) would be comparable to a cavernous cathedral and would impede clear communication.
Reverberation was reduced by providing ½” separations between individual wood planks at the ceiling, which allows sound to be absorbed in insulation above. The reverberation is still very long (about 2-1/2 seconds), but now people can communicate easily within about 6 feet of each other. Beyond that distance, speech is garbled, which effectively promotes privacy from most other occupants.
The buildup of sound from various occupant activities would be too noisy for the security guards, so security personnel were relocated under the lowest bridge, shielding them from the general lobby noise and reverberation.
A successful design is sensitive to the goals of the facility, manages reverberation, collects activities into shielded areas, and prevents distracting noise from transmitting to noise-sensitive spaces. Careful balancing of surface shaping, finish treatments, and sound isolation can deliver a great lobby.
IPEAL – FBA – Universidad Nacional de La Plata Calle 5 Nº 84 La Plata, 1900, ARGENTINA.
Popular version of 2pAA4, “Acoustical balance between the stage and the pit in the Teatro Colón of Buenos Aires” Presented Tuesday, May 08, 2018, 2:05pm – 2:25 PM, Nicollet C 175th ASA Meeting, Minneapolis Click here to read the abstract
Contrary to an auditorium for symphonic music, in which the orchestra and the audience occupy the same architectural space, an opera theatre has three different coupled spaces, each with different acoustic functions: the stage tower, the area for the audience and the orchestra pit. Given the importance of the voice in the genre, the sound balance B between the singers on the stage and the orchestra in the pit is considered one of the key factors that determine the acoustical quality of an opera performance [1]. In an opera theatre, the singers are at a disadvantage in comparison with the Orchestra, both in number and in sound power, and the balance B should be maintained within a range of -2 to +4 dB [2].
In the case of the Teatro Colón of Buenos Aires, well known for its outstanding acoustical quality [3], achieving the proper balance is not easy given its large size: a huge main volume of 20,000 m3 coupled to a stage tower of 30,000 m3.
Two different situations have been identified: the main floor and the upper levels. On the main floor, the measurements show that the balance is appropriate, with values of B between 0.7 and 4.7 dB. The analysis in a digital model reveals that these values were obtained from many broadband sound reflections of the singers’ voices on the surfaces surrounding the stalls (Fig. 1), in conjunction with the masking of the sound coming from the pit.
Figure 1. Some of the lateral reflections of the singers’ voice towards the same seat on the main floor, coming unobstructed from the dihedral angles wall/ceiling from three-balcony levels. They help the voice to be heard, and thus, rising the balance of the stalls.
As important as the values found of B is the spectral distribution of the balance. A singer trained in the western operatic tradition produces a lot of energy in a range of frequencies centred around 2500-3000 Hz. In this region, called the “singer’s formant”, they can reach intensities well above those of the orchestra [4]. In the Teatro Colón, the stage/pit balance reaches its maximum values in the region of the singer’s formant, helping the voices to be heard clearly (Fig. 2).
Figure 2. Spectral characteristics of the Balance on the main floor, in which the frequencies corresponding to the singer’s formant are reinforced and favored by the room.
As could be expected, the stage set-up can reduce the balance values on the main floor, mainly if the singer is placed well inside the stage tower.
At upper levels, where the instruments of the Orchestra in the pit can be seen, the balance loses part of the spectral advantage it has in the stalls; nevertheless, this situation is compensated by the emergence of the powerful reflection of the singers’ voice on the stage floor, reflection that is almost non-existent on the main floor (Fig.3). This fact, plus the appearance of early reflections coming from the ceiling, allows to maintain the balance within appropriate values at the higher levels.
Figure 3. Early reflections at the upper level (paraiso) from a directional source on the stage. The strong reflections can be seen on both the stage floor and the ceiling.
Video 1. Acoustical measurements of the Teatro Colón (IADAE, 2010)
The results of this work allow to understand some of the acoustic characteristics of the Teatro Colón. Those outcomes also enable us to design the set-ups of the operas based on acoustic considerations in order to keep the singer/orchestra balance at high levels, one of the key factors when it comes to qualifying a lyrical performance.
REFERENCES [1] N. Prodi, R. Pompoli, F. Martellotta, S. Sato. “Acoustics of Italian Historical Opera Houses”, J. Acoust. Soc. Am. 138 (2), 769-781, 2015. [2] J. Meyer. Acoustics and the Performance of Music, Springer, New York, 2009. [3] T. Hidaka, L. Beranek. “Objective and subjective evaluations of twenty-three opera houses in Europe, Japan, and the Americas”, J. Acoust. Soc. Am. 107 (1), 368-383, 2000. [4] J. Sundberg.J. The science of the singing voice, Northern Illinois University Press, Illinois, USA, 1987.


 These modern applications would benefit from an optimal T60SR6 grade:
These modern applications would benefit from an optimal T60SR6 grade:

 Figure 3: Reverb Time (T30) measurement for Lake Lethe
Figure 3: Reverb Time (T30) measurement for Lake Lethe Figure 4: Interior of the Wooden Bowl Room
Figure 4: Interior of the Wooden Bowl Room Figure 5: 1000ms waterfall analysis of Wooden Bowl Room showing a sustained resonance at 106.2 Hz
Figure 5: 1000ms waterfall analysis of Wooden Bowl Room showing a sustained resonance at 106.2 Hz Figure 6: Cleveland Avenue
Figure 6: Cleveland Avenue Figure 7: 1000ms waterfall analysis of Cleveland Avenue showing a sustained resonance at 118.6 Hz
Figure 7: 1000ms waterfall analysis of Cleveland Avenue showing a sustained resonance at 118.6 Hz










