
3pNS3 – Design of an Electric Vehicle Warning Sound System to Minimize Noise Pollution
Nikolaos Kournoutos – nk1y17@soton.ac.uk
Jordan Cheer – J.Cheer@soton.ac.uk
Institute of Sound and Vibration Research,
University of Southampton
University Rd
Southampton, UK SO17 1BJ
Popular version of paper 3pNS3 “Design and realisation of a directional electric vehicle warning sound system“
Presented 1:45pm, December 4, 2019
178th ASA Meeting, San Diego, CA
Read the article in Proceedings of Meetings on Acoustics
Electric cars are rather quiet when compared to their internal combustion counterparts, and this has sparked concern regarding the hazards this might impose on pedestrians and other vulnerable road users. As a result, regulations are coming into effect necessitating the adoption of artificial warning sounds by all electric cars. At the same time however, there have been numerous critics of this decision, citing the resulting increase in noise pollution it might bring about, along with all of its negative side effects.
Researchers have developed systems that are capable of focusing the emitted warning sounds at specific directions, in order to avoid any unnecessary emissions to the surrounding environments. Loudspeaker array based systems have been successful in that regard, managing to target individual pedestrians with the emitted warning sounds. However, the high manufacturing and maintenance costs have kept such solutions from being widely adopted.
In this project, we suggest a directional sound system, which instead of loudspeakers, utilizes an array of structural actuators. These actuators are capable of transmitting vibrations to the structure upon which they are attached, and cause it to radiate sound – effectively using the structure itself as a loudspeaker cone. Like with loudspeakers, one can control the phase and amplitude of each actuator in the array, so that the resulting vibration of the structure radiates sound towards a desired direction.
The first validation of the proposed system was performed using an actuator array attached on a simple rectangular panel. Measurements taken in an anechoic chamber indicate that the structural actuator array is indeed capable of directional sound radiation, within a frequency range defined by the physical characteristics of the vibrating structure.

Picture 1: The prototype used for evaluation consisted of a rectangular aluminum panel, and an array of six actuators attached to it.
The next step was to test how the system performs when implemented in an actual car. The geometry and different materials used in the components of a car mean that the performance of the system greatly depends on where the array is placed. We found that for the warning sounds we used in our tests, the best position for our array was the front bumper, which ensured good forward directivity, and reasonable sound beam steering capabilities.

Picture 2: The actuator array attached to a car for testing in a semi-anechoic environment.

Picture 3: Examples of the directivity achieved for different steering settings, when the actuator array is attached to the front bumper of the car. MATLAB Handle Graphics
Overall, results of our research show that a system based on structural actuators can generate controllable directional sound fields. More importantly, such a solution would be easier to implement on cars as it is more durable and requires no modifications. Wide adoption of such a system could ensure that electric cars can safely project an auditory warning without causing unnecessary noise pollution to the environment.





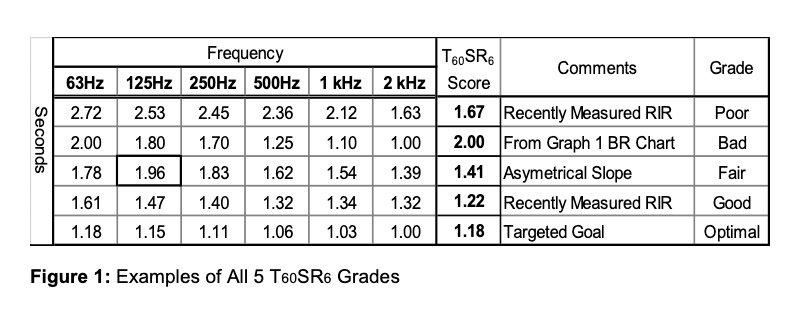

 These modern applications would benefit from an optimal T60SR6 grade:
These modern applications would benefit from an optimal T60SR6 grade: